Calcoliamo il coefficiente di correlazione e la covarianza per tipi diversi relazioni di variabili casuali.
Coefficiente di correlazione(criterio di correlazione Pearson, inglese Coefficiente di correlazione del momento prodotto di Pearson) determina il grado lineare relazioni tra variabili casuali.
Come segue dalla definizione, per calcolare coefficiente di correlazioneè necessario conoscere la distribuzione delle variabili casuali X e Y. Se le distribuzioni sono sconosciute, allora per stimare coefficiente di correlazione Usato coefficiente di correlazione campionariaR (è anche indicato come Rxy o rxy) :

dove S x – deviazione standard un campione di una variabile casuale x, calcolata dalla formula:

Come si può vedere dalla formula per il calcolo correlazioni, il denominatore (il prodotto delle deviazioni standard) normalizza semplicemente il numeratore in modo tale che correlazione risulta essere un numero adimensionale compreso tra -1 e 1. Correlazione e covarianza fornire le stesse informazioni (se note deviazioni standard ), ma correlazione più comodo da usare, perché è adimensionale.
Calcolare coefficiente di correlazione e covarianza campionaria in MS EXCEL non è difficile, poiché ci sono funzioni speciali CORREL() e COVAR() . È molto più difficile capire come interpretare i valori ottenuti, la maggior parte dell'articolo è dedicata a questo.
Digressione teorica
Richiama questo correlazione detta relazione statistica, consistente nel fatto che a diversi valori di una variabile corrispondono differenti medio valori di un altro (con una variazione del valore di X significare Y cambia in modo regolare). Si presume che entrambi le variabili X e Y sono casuale valori e hanno una dispersione casuale relativa ai loro valore medio.
Nota. Se solo una variabile, ad esempio Y, ha natura casuale e i valori dell'altra sono deterministici (impostati dal ricercatore), allora si può parlare solo di regressione.
Così, ad esempio, quando si studia la dipendenza della temperatura media annuale, non si può parlare correlazioni temperatura e anno di osservazione e, di conseguenza, applicare indicatori correlazioni con la rispettiva interpretazione.
correlazione tra le variabili può avvenire in diversi modi:
- La presenza di una relazione causale tra variabili. Ad esempio, l'importo dell'investimento in Ricerca scientifica(variabile X) e il numero di brevetti ricevuti (Y). La prima variabile appare come variabile indipendente (fattore), secondo - variabile dipendente (risultato). Va ricordato che la dipendenza delle quantità determina la presenza di una correlazione tra loro, ma non viceversa.
- La presenza di coniugazione (causa comune). Ad esempio, con la crescita dell'organizzazione, il fondo per le buste paga (PAY) e il costo dell'affitto dei locali crescono. Ovviamente, è sbagliato presumere che l'affitto dei locali dipenda dal libro paga. Entrambe queste variabili sono in molti casi linearmente dipendenti dal numero di dipendenti.
- Influenza reciproca delle variabili (quando cambia una variabile, cambia la seconda variabile e viceversa). Con questo approccio sono ammissibili due formulazioni del problema; Qualsiasi variabile può agire sia come variabile indipendente che come variabile dipendente.
In questo modo, indice di correlazione mostra quanto sia forte relazione lineare tra due fattori (se presenti) e la regressione consente di prevedere un fattore in base all'altro.
Correlazione, come qualsiasi altra statistica, può essere utile se utilizzata correttamente, ma presenta anche dei limiti nel suo utilizzo. Se mostra una relazione lineare chiaramente definita o una completa mancanza di relazione, allora correlazione riflette meravigliosamente. Ma, se i dati mostrano una relazione non lineare (ad esempio quadratica), la presenza di gruppi separati di valori o valori anomali, il valore calcolato coefficiente di correlazione può essere fuorviante (vedi file di esempio).
Correlazione vicino a 1 o -1 (cioè vicino in valore assoluto a 1) indica una forte relazione lineare di variabili, un valore vicino a 0 indica nessuna relazione. Positivo correlazione significa che con la crescita di un indicatore, l'altro, in media, aumenta e con un indicatore negativo diminuisce.
Per calcolare il coefficiente di correlazione è necessario che le variabili abbinate soddisfino le seguenti condizioni:
- il numero di variabili deve essere uguale a due;
- le variabili dovrebbero essere quantitative (es. frequenza, peso, prezzo). La media calcolata di queste variabili ha un chiaro significato: il prezzo medio o il peso medio del paziente. A differenza delle variabili quantitative, le variabili qualitative (nominali) prendono valori solo da un insieme finito di categorie (ad esempio, sesso o gruppo sanguigno). I valori numerici vengono confrontati condizionatamente a questi valori (ad esempio, femmina - 1 e maschio - 2). È chiaro che in questo caso il calcolo valore medio, che è necessario trovare correlazioni, non è corretto, il che significa che il calcolo del correlazioni;
- le variabili devono essere casuali e avere .
I dati bidimensionali possono avere una struttura diversa. Alcuni di essi richiedono approcci specifici con cui lavorare:
- Per dati non lineari correlazione deve essere usato con cautela. Per alcuni problemi può essere utile trasformare una o entrambe le variabili in modo da ottenere una relazione lineare (questo richiede di fare un'ipotesi sul tipo di relazione non lineare per suggerire il tipo di trasformazione desiderato).
- attraverso grafici a dispersione in alcuni dati si può osservare una variazione disuguale (scatter). Il problema con la variazione disuguale è che i luoghi con variazione elevata non solo forniscono le informazioni meno accurate, ma hanno anche la maggiore influenza nel calcolo. indicatori statistici. Questo problema viene spesso risolto anche trasformando i dati, ad esempio utilizzando un logaritmo.
- In alcuni dati si può osservare il raggruppamento, che può indicare la necessità di dividere la popolazione in parti.
- Un valore anomalo (anomalia) può distorcere il valore calcolato del coefficiente di correlazione. Un valore anomalo potrebbe essere dovuto al caso, a un errore nella raccolta dei dati o potrebbe effettivamente riflettere alcune caratteristiche della relazione. Poiché il valore anomalo si discosta fortemente dal valore medio, contribuisce notevolmente al calcolo dell'indicatore. Spesso le statistiche vengono calcolate con e senza valori anomali.
Utilizzo di MS EXCEL per calcolare la correlazione
Prendiamo 2 variabili come esempio X e Y e corrispondentemente, campionamento costituito da più coppie di valori (Х i ; Y i). Per chiarezza, costruiamo .
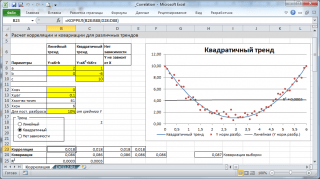
Nota: per ulteriori informazioni sulla creazione di grafici, vedere l'articolo. Nel file di esempio di build grafici a dispersione usato perché abbiamo qui deviato dal requisito che la variabile X sia casuale (questo semplifica la generazione vari tipi relazioni: costruire tendenze e una data diffusione). Nel caso di dati reali, è necessario utilizzare un grafico a dispersione (vedi sotto).
Calcoli correlazioni Tracciamo per vari casi la relazione tra le variabili: lineare, quadratico e a mancanza di comunicazione.
Nota: Nel file di esempio è possibile impostare i parametri della tendenza lineare (pendenza, intersezione con l'asse Y) e il grado di diffusione attorno a questa linea di tendenza. Puoi anche regolare le impostazioni di dipendenza quadratica.
Nel file di esempio di build grafici a dispersione nel caso di assenza di dipendenza delle variabili si utilizza un diagramma a dispersione. In questo caso, i punti del diagramma sono disposti a forma di nuvola.

Nota: Si noti che modificando la scala del grafico lungo l'asse verticale o orizzontale, è possibile conferire alla nuvola di punti l'aspetto di una linea verticale o orizzontale. È chiaro che in questo caso le variabili rimarranno indipendenti.
Come accennato in precedenza, per calcolare coefficiente di correlazione in MS EXCEL ci sono le funzioni CORREL(). Puoi anche usare la funzione PEARSON() simile, che restituisce lo stesso risultato.
Per assicurarsi i calcoli correlazioni sono prodotti dalla funzione CORREL() secondo le formule di cui sopra, il file di esempio mostra il calcolo correlazioni utilizzando formule più dettagliate:
=COVARIANZA.Y(B28:B88;D28:D88)/STDEV.Y(B28:B88)/STDEV.Y(D28:D88)
=COVARIATION.V(B28:B88;D28:D88)/STDEV.V(B28:B88)/STDEV.V(D28:D88)
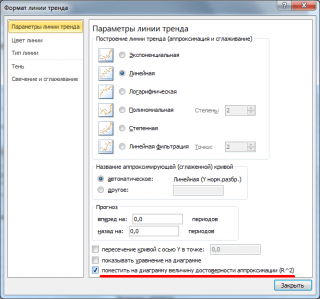
Nota: Quadrato coefficiente di correlazione r è coefficiente di determinazione R2, che viene calcolato quando si costruisce la retta di regressione utilizzando la funzione QVPIRSON(). È possibile visualizzare anche il valore di R2 grafico a dispersione, costruendo un trend lineare utilizzando la funzionalità standard di MS EXCEL (selezionare il grafico, selezionare la tab Disposizione, poi nel gruppo Analisi premi il bottone linea di tendenza e seleziona Approssimazione lineare). Per ulteriori informazioni sulla tracciatura di una linea di tendenza, vedere, ad esempio, .
Utilizzo di MS EXCEL per calcolare la covarianza
covarianza ha un significato vicino a (è anche una misura di dispersione), con la differenza che è definito per 2 variabili, e dispersione- per uno. Pertanto, cov(x;x)=VAR(x).

Per calcolare la covarianza in MS EXCEL (a partire dalla versione 2010), vengono utilizzate le funzioni COVARIATION.G() e COVARIATION.V(). Nel primo caso, la formula per il calcolo è simile alla precedente (finale .G sta per Popolazione), nel secondo - invece del fattore 1/n, viene utilizzato 1/(n-1), cioè fine .IN sta per Campione.
Nota: La funzione COVAR(), presente in MS EXCEL delle versioni precedenti, è simile alla funzione COVARIANCE.G().
Nota: Le funzioni CORREL() e COVAR() nella versione inglese sono rappresentate come CORREL e COVAR. Le funzioni COVARIANCE.G() e COVARIANCE.V() come COVARIANCE.P e COVARIANCE.S.
Formule aggiuntive per il calcolo covarianze:
=SOMMAPRODOTTO(B28:B88-MEDIA(B28:B88),(D28:D88-MEDIA(D28:D88))))/CONTEGGIO(D28:D88)
=SOMMAPRODOTTO(B28:B88-MEDIA(B28:B88),(D28:D88))/CONTEGGIO(D28:D88)
=SOMMAPRODOTTO(B28:B88,D28:D88)/CONTEGGIO(D28:D88)-MEDIA(B28:B88)*MEDIA(D28:D88)
Queste formule utilizzano la proprietà covarianze:
Se variabili X e y sono indipendenti, la loro covarianza è 0. Se le variabili non sono indipendenti, la varianza della loro somma è:
VAR(x+y)= VAR(x)+ VAR(y)+2COV(x;y)
MA dispersione la loro differenza è
VAR(x-y)= VAR(x)+ VAR(y)-2COV(x;y)
Valutazione della significatività statistica del coefficiente di correlazione
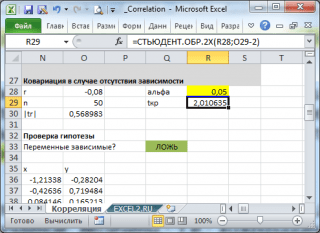
Per verificare l'ipotesi, dobbiamo conoscere la distribuzione della variabile casuale, cioè coefficiente di correlazione R. Di solito, il test di ipotesi viene eseguito non per r, ma per una variabile casuale t r:

che ha n-2 gradi di libertà.
Se il valore calcolato della variabile casuale |t r | maggiore del valore critico t α,n-2 (specificato con α), quindi ipotesi nulla rifiutato (la correlazione dei valori è statisticamente significativa).
Pacchetto di analisi aggiuntivo
B per calcolare la covarianza e la correlazione ci sono strumenti con lo stesso nome analisi.

Dopo aver chiamato lo strumento, viene visualizzata una finestra di dialogo che contiene i seguenti campi:

- intervallo di input: è necessario inserire un collegamento a un intervallo con dati iniziali per 2 variabili
- Raggruppamento: Generalmente, i dati grezzi vengono inseriti in 2 colonne
- Etichette sulla prima riga: se spuntato, allora intervallo di input deve contenere intestazioni di colonna. Si consiglia di selezionare la casella in modo che il risultato del componente aggiuntivo contenga colonne informative
- intervallo di uscita: l'intervallo di celle in cui verranno inseriti i risultati del calcolo. È sufficiente specificare la cella in alto a sinistra di questo intervallo.
Il componente aggiuntivo restituisce i valori di correlazione e covarianza calcolati (per la covarianza vengono calcolate anche le varianze di entrambe le variabili casuali).

Nel caso di una variabile casuale multidimensionale (vettore casuale), la caratteristica della diffusione delle sue componenti e delle relazioni tra di esse è la matrice di covarianza.
Matrice di covarianzaè definita come l'aspettativa matematica del prodotto di un vettore casuale centrato e lo stesso vettore ma trasposto:
dove 
La matrice di covarianza ha la forma

dove le diagonali sono le varianze delle coordinate del vettore casuale o n \u003d D Xi, o 22 \u003d D X2, o kk = D Xk e gli elementi rimanenti sono le covarianze tra le coordinate
° 12 \u003d M "x io x 2 j a 1 * \u003d M-jc, **\u003e
La matrice di covarianza è una matrice simmetrica, cioè ![]()
Si consideri ad esempio la matrice di covarianza di un vettore bidimensionale

Allo stesso modo, la matrice di covarianza si ottiene per qualsiasi vettore /^-dimensionale.
Le dispersioni di coordinate possono essere rappresentate come
dove Gi,C2,...,0? - deviazioni quadrate medie radice di coordinate vettoriali casuali.
Il coefficiente di correlazione è, come sapete, il rapporto tra la covarianza e il prodotto delle deviazioni standard:

Dopo la normalizzazione dell'ultimo rapporto dei termini della matrice di covarianza, si ottiene la matrice di correlazione

che è simmetrica e non negativa definita.
Un analogo multidimensionale della dispersione di una variabile casuale è la dispersione generalizzata, intesa come il valore del determinante della matrice di covarianza
![]()
Altro caratteristica comune il grado di dispersione di una variabile casuale multivariata è la traccia della matrice di covarianza
dove Ск - elementi diagonali della matrice di covarianza.
Spesso in multidimensionale analisi statistica viene utilizzata la distribuzione normale.
La funzione è una generalizzazione della densità di probabilità normale al caso di un vettore casuale ^-dimensionale
dove q = (pj, q 2 , M^) m - vettore colonna delle aspettative matematiche;
|X| - determinante della matrice di covarianza X;
1 - matrice di covarianza inversa.
Matrice X -1, inversa alla dimensione della matrice X ph p, può essere ottenuto diversi modi. Uno di questi è il metodo Jordan-Gauss. In questo caso, l'equazione della matrice
dove X- vettore colonna di variabili il cui numero è uguale a i; B- vettore colonna i-dimensionale delle parti destre.
Moltiplica l'equazione (6.21) a sinistra per la matrice inversa ХГ 1:
![]()
Dal momento che il lavoro matrice inversa fornisce la matrice identità E, poi
![]()
Se invece B prendi il vettore dell'unità

quindi il prodotto X -1 -ex dà la prima colonna della matrice inversa. Se prendiamo il secondo vettore unitario

quindi il prodotto E 1 e 2 fornisce la prima colonna della matrice inversa e così via. Quindi, risolvendo successivamente le equazioni
![]()
utilizzando il metodo di Jordan-Gauss, otteniamo tutte le colonne della matrice inversa.
Un altro metodo per ottenere una matrice inversa alla matrice E è relativo al calcolo dei complementi algebrici Un tJ .= (/= 1, 2,..., P; j = 1, 2, ..., P) agli elementi della data matrice E, sostituendoli al posto degli elementi della matrice E e trasportando tale matrice:

La matrice inversa si ottiene dopo aver diviso gli elementi IN al determinante della matrice E:
Una caratteristica importante per ottenere la matrice inversa in questo caso è che la matrice di covarianza E è debolmente condizionata. Ciò porta al fatto che possono verificarsi errori piuttosto seri quando si invertono tali matrici. Tutto ciò richiede la garanzia della necessaria accuratezza del processo di calcolo o l'uso di metodi speciali nel calcolo di tali matrici.
Esempio. Scrivi un'espressione di densità di probabilità per una variabile casuale bidimensionale normalmente distribuita (X contro X 2)
a condizione che le aspettative matematiche, varianze e covarianze di queste grandezze abbiano i seguenti valori:
Soluzione. La matrice di covarianza inversa per la matrice (6.19) può essere ottenuta utilizzando la seguente espressione di matrice inversa per la matrice X:

dove A è il determinante della matrice X.
A e, L 12, A 21, A 22- addizioni algebriche ai corrispondenti elementi della matrice X.
Allora per la matrice ]r- ! otteniamo l'espressione

Poiché a 12 \u003d 01O2P e ° 2i \u003d a 2 a iP\u003e a i2 a 2i \u003d cyfst | p, allora

Troviamo il prodotto


La funzione di densità di probabilità può essere scritta come

Sostituendo i dati iniziali, otteniamo la seguente espressione per la funzione di densità di probabilità

Consideriamo la tecnica per calcolare la covarianza e la correlazione dei rendimenti dei titoli utilizzando un esempio.
Il rendimento sulla carta X per cinque anni è stato rispettivamente del 20%, 25%, 22%, 28%, 24%. Rendimento su carta F: 24%, 28%, 25%, 27%, 23%. Determina la covarianza dei rendimenti azionari.
Risolviamo il problema in due modi.
a) Stampa su ordine cronologico nelle celle con Al no A5, i valori di resa della carta X e nelle celle da B1 a B5, la resa della carta F. Otterremo la soluzione nella cella C1, quindi passiamoci sopra e facciamo clic con il mouse. Stampiamo nella cella C1 la formula:
e premere il tasto Invio. Nella cella C1 è apparsa una soluzione al problema: il numero 3.08, ad es. covarianza campionaria per il nostro esempio.
b) La covarianza può essere calcolata utilizzando il programma "Function Wizard". Per fare ciò, passa il mouse sopra l'icona A sulla barra degli strumenti e fai clic con il mouse. Viene visualizzata la finestra della procedura guidata. Nel campo di sinistra ("Categoria"), sposta il cursore sulla riga "Statistica" e fai clic con il mouse. La linea è stata evidenziata in blu e nel campo destro della finestra ("Funzione") è apparso un elenco di funzioni statistiche. Posizionare il cursore sulla riga "KOVAR" e fare clic con il tasto sinistro del mouse. La linea è evidenziata in blu. Posizionare il cursore sul pulsante OK e fare clic con il mouse. Apparve la finestra "KOVAR". Nella finestra sono presenti due righe, denominate "Array 1" e "Array 2". Nella prima riga inseriamo i numeri di cella da A1 a A5. Per fare ciò, sposta il cursore sul segno 3 situato sul lato destro della prima riga e fai clic con il mouse. La finestra "KOVAR" si è trasformata in un campo di prima linea. Posizionare il cursore sulla cella A1, premere il tasto sinistro del mouse e, tenendolo premuto, spostare il cursore in basso sulla cella A5 e rilasciare il tasto. La voce A1:A5 è apparsa nel campo della riga. Passa di nuovo sopra il segno e fare clic con il mouse. Apparve la finestra ampliata "KOVAR". Inseriamo i numeri di cella con Bl no B5 nella seconda riga. Per fare ciò, sposta il cursore sul segno 5J nella seconda riga e fai clic con il mouse. Posizionare il cursore sulla cella B1, premere il tasto sinistro del mouse e, tenendolo premuto, spostare il cursore in basso sulla cella B5, rilasciare il tasto. La voce B1:B5 è apparsa nel campo della riga. Passa il mouse sopra il pulsante 3| e fare clic con il mouse. Apparve la finestra ampliata "KOVAR". Posizionare il cursore sul pulsante OK e fare clic con il mouse. Il numero 3.08 è apparso nella cella C1.
Determinare il coefficiente di correlazione dei rendimenti dei titoli per le condizioni dell'esempio 1. Soluzione. Risolviamo il problema in due modi.
a) Stampiamo in ordine cronologico nelle celle con Al no A5 i valori di resa della carta X e nelle celle da B1 a B5 - la resa della carta F. Otteniamo la soluzione nella cella C1, quindi ci passiamo sopra e fare clic con il mouse. Stampiamo nella cella C1 la formula:
![]()
e premere il tasto Invio. Nella cella C1 è apparsa una soluzione al problema: il numero 0,612114.
b) La correlazione può essere calcolata utilizzando la "Funzione guidata". Per fare ciò, selezionare l'icona l sulla barra degli strumenti con il cursore e fare clic con il mouse. Viene visualizzata la finestra della procedura guidata. Nel campo di sinistra ("Categoria"), selezionare la riga "Statistica" con il cursore e fare clic con il mouse. Nel campo destro della finestra ("Funzione") è apparso un elenco di funzioni statistiche. Selezionare la riga "CORREL" con il cursore e fare clic con il mouse. La linea è evidenziata in blu. Posizionare il cursore sul pulsante OK e fare clic con il mouse. Appare la finestra "CORREL". Nella finestra sono presenti due righe, denominate "Array 1" e "Array 2". Nella prima riga inseriamo i numeri di cella con Al no A5. Per fare ciò, sposta il cursore sul segno ZP a destra della prima riga e fai clic con il mouse. La finestra "CORREL" è diventata il campo della prima riga. Posizionare il cursore sulla cella A1, premere il tasto sinistro del mouse e, tenendolo premuto, spostare il cursore in basso sulla cella A5 e rilasciare il tasto. La voce A1:A5 è apparsa nel campo della riga. Posizionare nuovamente il cursore sul segno U e fare clic con il mouse. Appariva la finestra "CORREL" espansa. Inseriamo i numeri di cella con Bl no B5 nella seconda riga. Per fare ciò, sposta il cursore sul segno W nella seconda riga e fai clic con il mouse. Posizionare il cursore sulla cella B1, premere il tasto sinistro del mouse e, tenendolo premuto, spostare il cursore in basso sulla cella B5, rilasciare il tasto. La voce B1:B5 è apparsa nel campo della riga. Spostare il cursore sul pulsante Щ e fare clic con il mouse. Appariva la finestra "CORREL" espansa. Posizionare il cursore sul pulsante OK e fare clic con il mouse. Il numero 0,612114 è apparso nella cella C1.
Negli esempi 1 e 2 abbiamo calcolato la covarianza e la correlazione dei rendimenti di due titoli in portafoglio. Se il portafoglio include più titoli, le covarianze e le correlazioni dei loro rendimenti possono essere calcolate in coppia utilizzando il metodo sopra descritto, ma questa è una variante laboriosa per risolvere il problema. Excel ha uno speciale pacchetto di analisi dei dati che ti consente di risolvere rapidamente un problema del genere un largo numero carte. Considera il calcolo della covarianza e delle correlazioni con il suo aiuto.
Lo sai che: Il broker Forex "NPBFX" porta assolutamente tutte le transazioni dei suoi clienti ai fornitori di liquidità (al mercato interbancario), lavorando su Tecnologie STP/NDD(Elaborazione diretta - tramite elaborazione delle transazioni / Non Dealing Desk).


"Analysis Pack" potrebbe non essere installato. Quindi deve essere installato. Per fare ciò, passa con il mouse sul menu "Strumenti" e fai clic con il pulsante sinistro del mouse. È apparso un menu a discesa. Selezionare il comando "Componenti aggiuntivi" con il cursore e fare clic con il tasto sinistro del mouse. Viene visualizzata la finestra di dialogo Componenti aggiuntivi. Spostare il cursore sulla casella a sinistra della riga "Pacchetto di analisi" e fare clic con il pulsante sinistro del mouse. C'è un segno di spunta nella casella. Posizionare il cursore sul pulsante OK e fare clic con il mouse. "Pacchetto di analisi" è installato. Considera la definizione di covarianza e correlazioni per diversi titoli usando un esempio.
Esempio 3: calcolo della covarianza
Esiste un campione di dati sui rendimenti dei titoli B, C e D per dieci periodi. Stampiamo i valori di resa per carta B nelle celle da B1 a B10, carta C da C1 a CJ e carta D da D1 a D10, come mostrato in fig. 1.8. Passa il mouse sopra il menu "Strumenti" e fai clic con il pulsante sinistro del mouse. È apparso un menu a discesa. Posizionare il cursore sulla riga "Analisi dei dati" e fare clic con il tasto sinistro del mouse. Viene visualizzata la finestra Analisi dati. Posizionare il cursore sulla riga "Covarianza" e fare clic con il tasto sinistro del mouse. La linea è evidenziata in blu. Posizionare il cursore sul pulsante OK e fare clic con il mouse. Appare la finestra "Covarianza" (vedi Fig. 1.10).


Posizionare il cursore sul segno 3 a destra del campo della riga "Intervallo di immissione" e fare clic con il mouse. La finestra "Covarianza" è compressa in una casella di riga. Posizionare il cursore sulla cella B1, premere il tasto sinistro del mouse e, tenendolo premuto, trascinare sulla cella D10. Nella riga è apparsa la voce $B$1:$D$10. Spostare nuovamente il cursore sul segno e fare clic con il mouse. Viene visualizzata la finestra Covarianza espansa. I dati sono raggruppati per colonne. Pertanto, se non è presente alcun punto nella finestra rotonda a sinistra dell'iscrizione "in colonne", puntare il cursore su di esso e fare clic con il pulsante sinistro del mouse. Un punto apparirà nella finestra. Di seguito è riportata la riga "Intervallo di output". Dovrebbe esserci un punto nella finestra rotonda a sinistra dell'iscrizione. Se non è presente, sposta il cursore su questa riga e fai clic con il pulsante sinistro del mouse. Un punto apparirà nella finestra. Posizionare il cursore sul segno 3 a destra del campo della riga "Intervallo di output" e fare clic con il mouse. La finestra "Covarianza" è diventata un campo stringa. Prendiamo la cella A12 come inizio dell'intervallo di output. Pertanto, passiamo con il mouse su di esso e premiamo il pulsante sinistro del mouse. La voce $A$12 è apparsa nel campo della stringa. Posizionare nuovamente il cursore sul segno 3 e fare clic con il mouse. La finestra "Covarianza" si è espansa. Posizionare il cursore sul pulsante OK e fare clic con il mouse. La soluzione al problema è apparsa sul foglio come mostrato in Fig. 1.11. Nel blocco da B13 a D15 viene presentata la matrice di covarianza. Lungo la sua diagonale, cioè nelle celle B13, C14 e B15 sono presenti le dispersioni rispettivamente dei titoli B, C e D, nelle restanti celle - la covarianza dei rendimenti dei titoli: nella cella B14 la covarianza dei rendimenti dei titoli B e C, in B15 - i titoli B e D, in C15 - titoli C e D .

Esempio 4 Calcolo delle correlazioni
Esiste un campione di dati sui rendimenti di tre titoli - B, C e D - per dieci periodi. Come nel problema 3, stampiamo i valori di resa per la carta B nelle celle da B1 a B10, per la carta C da C1 a C10 e per la carta D da D1 a D10 (Fig. 1.9). Passa il mouse sopra il menu "Strumenti" e fai clic con il pulsante sinistro del mouse. È apparso un menu a discesa. Posizionare il cursore sulla riga "Analisi dei dati" e fare clic con il tasto sinistro del mouse. Viene visualizzata la finestra Analisi dati. Posizionare il cursore sulla riga "Correlazione" e fare clic con il tasto sinistro del mouse. La linea è evidenziata in blu. Posizionare il cursore sul pulsante OK e fare clic con il mouse. È apparsa la finestra di correlazione (è simile nella struttura alla finestra "Covarianza"). Posizionare il cursore sul segno 3 a destra del campo della riga "Intervallo di immissione" e fare clic con il mouse. La finestra "Correlazione" è compressa in una casella di riga. Posizionare il cursore sulla cella B1, premere il tasto sinistro del mouse e, tenendolo premuto, spostare il cursore sulla cella D10. Nella riga è apparsa la voce $B$1:$D$10. Spostare nuovamente il cursore sul segno e fare clic con il mouse. Viene visualizzata la finestra espansa "Correlazione". I dati sono raggruppati per colonne. Pertanto, se non è presente alcun punto nella finestra rotonda a sinistra dell'iscrizione "in colonne", puntare il cursore su di esso e fare clic con il pulsante sinistro del mouse. Un punto apparirà nella finestra. Di seguito è riportata la riga "Intervallo di output". Dovrebbe esserci un punto nella finestra rotonda a sinistra dell'iscrizione. Se non è presente, sposta il cursore su questa riga e fai clic con il pulsante sinistro del mouse. Un punto apparirà nella finestra. Posizionare il cursore sul segno 3 a destra del campo della riga "Intervallo di output" e fare clic con il mouse. La finestra "Correlazione" è diventata un campo stringa. Prendiamo la cella A12 come inizio dell'intervallo di output. Pertanto, passiamo con il mouse su di esso e premiamo il pulsante sinistro del mouse. La voce $A$12 è apparsa nel campo della stringa. Posizionare nuovamente il cursore sul segno 3 e fare clic con il mouse. La finestra "Correlazione" si è espansa. Posizionare il cursore sul pulsante OK e fare clic con il mouse. La soluzione al problema è apparsa sul foglio come mostrato in Figura 1.12. Il blocco da B13 a D15 presenta la matrice di correlazione. Lungo la sua diagonale, cioè nelle celle B13, C14 e D15 sono presenti le quote, nelle restanti celle - correlazioni dei rendimenti dei titoli: nella cella B14 la correlazione dei rendimenti dei titoli B e C, in B15 - titoli B e D, in C15 - titoli C e D .

Contenuto
Questo articolo descrive la sintassi della formula e l'utilizzo della funzione COVARIAZIONE.G in Microsoft Excel.
Restituisce la covarianza della popolazione, la media aritmetica dei prodotti delle varianze per ciascuna coppia di punti dati in due set di dati. La covarianza viene utilizzata per determinare la relazione tra due insiemi di dati. Ad esempio, puoi verificare se un livello di reddito più alto corrisponde a più alto livello formazione scolastica.
Sintassi
COVARIANZA.G(array1,array2)
La sintassi della funzione COVARIANZA.G ha i seguenti argomenti:
Matrice1è un argomento obbligatorio. Il primo intervallo di celle con numeri interi.
Matrice2è un argomento obbligatorio. Il secondo intervallo di celle con numeri interi.
Osservazioni
Esempio
Copia i dati di esempio dalla tabella seguente e incollali nella cella A1 di un nuovo foglio Excel. Per visualizzare i risultati della formula, selezionarli e premere F2 seguito da INVIO. Modificare la larghezza delle colonne, se necessario, per vedere tutti i dati.
Quante volte hai sentito affermazioni che dicevano che un fenomeno è correlato a un altro?
“L'elevata crescita è correlata a buona educazione e felicità, hanno scoperto gli esperti del servizio sociologico Gallup.
"Il prezzo del petrolio è correlato ai tassi di cambio".
"Il dolore muscolare dopo l'esercizio non è correlato all'ipertrofia delle fibre muscolari".
Si ha l'impressione che il concetto di "correlazione" sia diventato ampiamente utilizzato non solo nella scienza, ma anche in Vita di ogni giorno. La correlazione riflette il grado dipendenza lineare tra due eventi casuali. Quindi, quando i prezzi del petrolio iniziano a scendere, il dollaro nei confronti del rublo inizia a salire.
Da tutto quanto sopra, possiamo concludere che quando si descrivono variabili casuali bidimensionali, non ce ne sono abbastanza buone caratteristiche note, come aspettativa matematica, varianza, deviazione standard. Pertanto, per descriverli vengono spesso utilizzate altre due caratteristiche molto importanti: covarianza e correlazione.
covarianza
covarianza$cov\left(X,\ Y\right)$ di variabili casuali $X$ e $Y$ è l'aspettativa del prodotto di variabili casuali $XM\left(X\right)$ e $YM\left(Y\ giusto)$, ovvero:
$$cov\sinistra(X,\Y\destra)=M\sinistra(\sinistra(XM\sinistra(X\destra)\destra)\sinistra(YM\sinistra(Y\destra)\destra)\destra). $$
Può essere conveniente calcolare la covarianza di variabili casuali $X$ e $Y$ usando la seguente formula:
$$cov\sinistra(X,\Y\destra)=M\sinistra(XY\destra)-M\sinistra(X\destra)M\sinistra(Y\destra),$$
che può essere ottenuto dalla prima formula usando le proprietà dell'aspettativa matematica. Elenchiamo i principali proprietà di covarianza.
1 . La covarianza di una variabile casuale con se stessa è la sua varianza.
$$cov\sinistra(X,\X\destra)=D\sinistra(X\destra).$$
2 . La covarianza è simmetrica.
$$cov\sinistra(X,\Y\destra)=cov\sinistra(Y,\X\destra).$$
3 . Se le variabili casuali $X$ e $Y$ sono indipendenti, allora:
$$cov\sinistra(X,\Y\destra)=0.$$
4 . Il fattore costante può essere estratto dal segno di covarianza.
$$cov\left(cX,\Y\right)=cov\left(X,\ cY\right)=c\cdot cov\left(X,\ Y\right).$$
5 . La covarianza non cambierà se un valore costante viene aggiunto a una delle variabili casuali (o due contemporaneamente):
$$cov\sinistra(X+c,\ Y\destra)=cov\sinistra(X,\ Y+c\destra)=cov\sinistra(X+x,\ Y+c\destra)=cov\sinistra( X,\Y\destra).$$
6 . $cov\sinistra(aX+b,\ cY+d\destra)=ac\cdot cov\sinistra(X,\ Y\destra)$.
7 . $\sinistra|cov\sinistra(X,\Y\destra)\destra|\le \sqrt(D\sinistra(X\destra)D\sinistra(Y\destra))$.
8 . $\sinistra|cov\sinistra(X,\ Y\destra)\destra|=\sqrt(D\sinistra(X\destra)D\sinistra(Y\destra))\Sinistradestrafreccia Y=aX+b$.
9 . La varianza della somma (differenza) delle variabili casuali è uguale alla somma delle loro varianze più (meno) il doppio della covarianza di queste variabili casuali:
$$D\sinistra(X\pm Y\destra)=D\sinistra(X\destra)+D\sinistra(Y\destra)\pm 2cov\sinistra(X,\ Y\destra).$$
Esempio 1 . Viene fornita la tabella di correlazione del vettore casuale $\left(X,\Y\right)$. Calcola la covarianza $cov\left(X,\Y\right)$.
$\begin(array)(|c|c|)
\hline
\hline
-2 & 0,1 & 0 & 0,2 \\
\hline
0 e 0,05 e p_(22) e 0 \\
\hline
1 & 0 & 0,2 & 0,05 \\
\hline
7 & 0,1 & 0 & 0,1 \\
\hline
\end(array)$
Gli eventi $\left(X=x_i,\ Y=y_j\right)$ formano un gruppo completo di eventi, quindi la somma di tutte le probabilità $p_(ij)$ fornite nella tabella deve essere uguale a 1. Quindi $0, 1+0+0 ,2+0.05+p_(22)+0+0+0.2+0.05+0.1+0+0.1=1$, quindi $p_(22)=0.2$.
$\begin(array)(|c|c|)
\hline
X\barra inversa Y & -6 & 0 & 3 \\
\hline
-2 & 0,1 & 0 & 0,2 \\
\hline
0 & 0,05 & 0,2 & 0 \\
\hline
1 & 0 & 0,2 & 0,05 \\
\hline
7 & 0,1 & 0 & 0,1 \\
\hline
\end(array)$
Usando la formula $p_(i) =\sum _(j)p_(ij) $, troviamo la serie di distribuzione della variabile casuale $X$.
$\begin(array)(|c|c|)
\hline
X e -2 e 0 e 1 e 7 \\
\hline
p_i e 0,3 e 0,25 e 0,25 e 0,2 \\
\hline
\end(array)$
$$M\sinistra(X\destra)=\somma^n_(i=1)(x_ip_i)=-2\cpunto 0.3+0\cpunto 0.25+1\cpunto 0.25+7\cpunto 0 ,2=1.05.$ $
$$D\sinistra(X\destra)=\somma^n_(i=1)(p_i(\sinistra(x_i-M\sinistra(X\destra)\destra))^2)=0.3\cdot ( \sinistra (-2-1.05\destra))^2+0.25\cpunto (\sinistra(0-1.05\destra))^2+0.25\cpunto (\sinistra(1-1, 05\destra))^2+$$
$$+\ 0,2\cpunto (\sinistra(7-1,05\destra))^2=10,1475.$$
$$\sigma \left(X\right)=\sqrt(D\left(X\right))=\sqrt(10,1475)\circa 3,186.$$
Usando la formula $q_(j) =\sum _(i)p_(ij) $, troviamo la serie di distribuzione della variabile casuale $Y$.
$\begin(array)(|c|c|)
\hline
S e -6 e 0 e 3 \\
\hline
p_i e 0,25 e 0,4 e 0,35 \\
\hline
\end(array)$
$$M\sinistra(Y\destra)=\somma^n_(i=1)(y_ip_i)=-6\cpunto 0.25+0\cpunto 0.4+3\cpunto 0.35=-0.45 .$$
$$D\sinistra(Y\destra)=\somma^n_(i=1)(p_i(\sinistra(y_i-M\sinistra(Y\destra)\destra))^2)=0,25\cdot (\sinistra (-6+0,45\destra))^2+0,4\cpunto (\sinistra(0+0,45\destra))^2+0,35\cpunto (\sinistra(3+0, 45\destra))^2=11,9475. $$
$$\sigma \left(Y\right)=\sqrt(D\left(Y\right))=\sqrt(11,9475)\circa 3,457.$$
Poiché $P\left(X=-2,\ Y=-6\right)=0.1\ne 0.3\cdot 0.25$, le variabili casuali $X,\ Y$ sono dipendenti.
Definiamo la covarianza $cov\ \left(X,\ Y\right)$ di variabili casuali $X,\ Y$ con la formula $cov\left(X,\ Y\right)=M\left(XY\right) )-M\ sinistra(X\destra)M\sinistra(Y\destra)$. Valore atteso il prodotto di variabili casuali $X,\ Y$ è uguale a:
$$M\left(XY\right)=\sum_(i,\ j)(p_(ij)x_iy_j)=0,1\cdot \left(-2\right)\cdot \left(-6\right) +0.2\cdot \left(-2\right)\cdot 3+0.05\cdot 1\cdot 3+0.1\cdot 7\cdot \left(-6\right)+0.1\cdot 7\cdot 3=-1.95. $$
Quindi $cov\left(X,\Y\right)=M\left(XY\right)-M\left(X\right)M\left(Y\right)=-1.95-1.05\cdot \left(- 0,45\right)=-1,4775.$ Se le variabili casuali sono indipendenti, la loro covarianza è zero. Nel nostro caso $cov(X,Y)\ne 0$.
Correlazione
Coefficiente di correlazione le variabili casuali $X$ e $Y$ sono chiamate numero:
$$\rho \left(X,\ Y\right)=((cov\left(X,\ Y\right))\over (\sqrt(D\left(X\right)D\left(Y\right) )))).$$
Elenchiamo i principali proprietà del coefficiente di correlazione.
1 . $\rho \sinistra(X,\ X\destra)=1$.
2 . $\rho \sinistra(X,\ Y\destra)=\rho \sinistra(Y,\ X\destra)$.
3 . $\rho \left(X,\ Y\right)=0$ per variabili casuali indipendenti $X$ e $Y$.
4 . $\rho \left(aX+b,\ cY+d\right)=(sgn \left(ac\right)\rho \left(X,\ Y\right)\ )$, dove $(sgn \left( ac\right)\ )$ è il segno del prodotto $ac$.
5 . $\sinistra|\rho \sinistra(X,\ Y\destra)\destra|\le 1$.
6 . $\sinistra|\rho \sinistra(X,\ Y\destra)\destra|=1\Sinistradestrafreccia Y=aX+b$.
In precedenza si è detto che il coefficiente di correlazione $\rho \left(X,\Y\right)$ riflette il grado di relazione lineare tra due variabili casuali $X$ e $Y$.
Per $\rho \left(X,\ Y\right)>0$, possiamo concludere che come variabile casuale $X$ valore casuale$Y$ tende ad aumentare. Questa è chiamata correlazione positiva. Ad esempio, l'altezza e il peso di una persona sono correlati positivamente.
Per $\rho \sinistra(X,\Y\destra)<0$ можно сделать вывод о том, что с ростом случайной величины $X$ случайная величина $Y$ имеет тенденцию к уменьшению. Это называется отрицательной корреляционной зависимостью. Например, температура и время сохранности продуктов питания связаны между собой отрицательной корреляционной зависимостью.
Per $\rho \left(X,\ Y\right)=0$ le variabili casuali $X$ e $Y$ sono chiamate non correlate. Va notato che la non correlazione delle variabili casuali $X$ e $Y$ non significa la loro indipendenza statistica, significa solo che non esiste una relazione lineare tra di loro.
Esempio 2 . Determiniamo il coefficiente di correlazione $\rho \left(X,\ Y\right)$ per la variabile casuale bidimensionale $\left(X,\ Y\right)$ dall'Esempio 1.
Il coefficiente di correlazione delle variabili casuali $X,\ Y$ è $r_(XY) =(cov(X,Y)\over \sigma (X)\sigma (Y)) =(-1.4775\over 3.186\cdot 3.457 ) =-0.134.$ Da $r_(XY)<0$, то с ростом $X$ случайная величина $Y$ имеет тенденцию к уменьшению (отрицательная корреляционная зависимость).