A véletlenszerű jelenségek tanulmányozásának gyakorlata azt mutatja, hogy bár az egyedi megfigyelések eredményei, még az azonos körülmények között végzett megfigyelések eredményei is nagymértékben eltérhetnek, ugyanakkor az átlagos eredmények kellően nagy számú megfigyelés esetén stabilak és gyengén függnek a megfigyelésektől. egyéni megfigyelések eredményei.
A véletlenszerű jelenségek e figyelemre méltó tulajdonságának elméleti igazolása az nagy számok törvénye. A "nagy számok törvénye" elnevezés olyan tételek csoportját egyesíti, amelyek megállapítják nagyszámú véletlenszerű jelenség átlageredményének stabilitását, és megmagyarázzák ennek a stabilitásnak az okát.
A nagy számok törvényének legegyszerűbb formája, történetileg pedig e szakasz első tétele az Bernoulli tétele kimondva, hogy ha egy esemény valószínűsége minden kísérletben azonos, akkor a kísérletek számának növekedésével az esemény gyakorisága az esemény valószínűségére hajlik, és megszűnik véletlenszerű lenni.
A Poisson-tétel kimondja, hogy egy esemény gyakorisága független kísérletek sorozatában a valószínűségek számtani átlagához hajlik, és megszűnik véletlenszerű lenni.
Valószínűségszámítás határtételei, tételek Moivre-Laplace magyarázza el egy esemény előfordulási gyakoriságának stabilitásának természetét. Ez a természet abban áll, hogy egy esemény előfordulási számának korlátozó eloszlása a kísérletek számának korlátlan növekedésével (ha az esemény valószínűsége minden kísérletben azonos) normális eloszlás.
A centrális határérték tétel magyarázza a széleskörű használatot normális törvény terjesztés. A tétel kimondja, hogy amikor egy valószínűségi változó nagyszámú, véges varianciájú független valószínűségi változó összeadásával jön létre, ennek a valószínűségi változónak az eloszlási törvénye gyakorlatilag Normál törvény szerint.
Az alábbi tétel: " A nagy számok törvénye" azt állítja, hogy bizonyos, meglehetősen általános feltételek mellett, a valószínűségi változók számának növekedésével ezek számtani átlaga a matematikai elvárások számtani átlagához hajlik, és megszűnik véletlenszerű lenni.
Ljapunov tétele megmagyarázza az elterjedt normális törvény eloszlását és elmagyarázza kialakulásának mechanizmusát. A tétel lehetővé teszi annak állítását, hogy amikor egy valószínűségi változó nagyszámú független valószínűségi változó összeadásával jön létre, amelyek szórása kicsi az összeg szórásához képest, akkor ennek a valószínűségi változónak az eloszlási törvénye kiderül, hogy gyakorlatilag legyen Normál törvény szerint. És mivel a valószínűségi változókat mindig végtelen számú ok generálja, és leggyakrabban egyiknek sincs olyan szórása, amely összemérhető legyen magának a valószínűségi változónak, a gyakorlatban előforduló valószínűségi változók többsége a normál eloszlási törvény hatálya alá tartozik.
A nagy számok törvényének minőségi és mennyiségi állításai azon alapulnak Csebisev egyenlőtlensége. Meghatározza annak a valószínűségének felső korlátját, hogy egy valószínűségi változó értékének eltérése a matematikai elvárásától nagyobb, mint egy adott szám. Figyelemre méltó, hogy a Csebisev-egyenlőtlenség becslést ad az esemény valószínűségére egy ismeretlen eloszlású valószínűségi változónál csak a matematikai elvárása és varianciája ismert.
Csebisev egyenlőtlensége. Ha egy x valószínűségi változónak van szórása, akkor bármely e > 0 esetén az egyenlőtlenség ![]() , ahol M x és D x - az x valószínűségi változó matematikai elvárása és varianciája.
, ahol M x és D x - az x valószínűségi változó matematikai elvárása és varianciája.
Bernoulli tétele. Legyen m n az n Bernoulli-próba sikereinek száma, p pedig az egyetlen próba sikerének valószínűsége. Ekkor bármely e > 0-ra ![]() .
.
Központi határérték tétel. Ha az x 1 , x 2 , …, x n , … valószínűségi változók páronként függetlenek, egyenlő eloszlásúak és véges szórással rendelkeznek, akkor n ® -nél egyenletesen x-ben (- ,)
NAGY SZÁMOK TÖRVÉNYE
általános elv, amelynek értelmében a véletlenszerű tényezők kombinációja bizonyos nagyon általános feltételek mellett a véletlentől szinte független eredményhez vezet. Egy véletlenszerű esemény előfordulási gyakoriságának konvergenciája annak valószínűségével a próbák számának növekedésével (elsőként nyilvánvalóan a szerencsejátékoknál) szolgálhat ennek az elvnek az első példájaként.
A 17. és 18. század fordulóján. J. Bernoulli bebizonyított egy tételt, amely szerint független kísérletek sorozatában, amelyek mindegyikében egy bizonyos A esemény előfordulása azonos értékű, az összefüggés igaz:
bármely - az esemény előfordulásának száma az első próbákban, - az előfordulások gyakorisága. Ez Bernoulli tétel S. Poisson kiterjesztette egy független kísérletsorozat esetére, ahol az A esemény bekövetkezésének valószínűsége függhet a próbaszámtól. Legyen ez a valószínűség a k-edik próba esetén egyenlő, és legyen
![]()
Azután Poisson-tétel azt állítja
Bármelyre ennek a tételnek az első szigorúságát PL Chebisev (1846) adta meg, akinek módszere teljesen eltér Poisson módszerétől, és bizonyos szélsőséges megfontolásokon alapul; S. Poisson a (2)-t a megadott valószínűség közelítő képletéből vezette le, a Gauss-törvény felhasználása alapján, és akkor még nem volt szigorúan alátámasztva. S. Poisson először találkozott a "nagy számok törvénye" kifejezéssel is, amelyet Bernoulli tételének általánosításának nevezett.
A Bernoulli- és Poisson-tétel természetes további általánosítása, ha megjegyezzük, hogy a valószínűségi változók összegként is ábrázolhatók.
független valószínűségi változók, ahol ha A megjelenik az Ath-próbában, és
- másképp. Ugyanakkor matematikai elvárás (amely egybeesik a matematikai elvárások számtani átlagával) egyenlő p-vel Bernoulli és Poisson esetére. Vagyis mindkét esetben a számtani átlag eltérését veszik figyelembe X k a számtani átlaguktól a matematikai. elvárások.
P. L. Csebisev "Átlagos értékek" (1867) című munkájában megállapították, hogy a független valószínűségi változók esetében a kapcsolat
(bármely ) nagyon általános feltételezések alapján igaz. P. L. Csebisev feltételezte, hogy a matematikai. az elvárásokat ugyanaz a konstans határolja, bár a bizonyítása alapján világos, hogy elegendő megkövetelni, hogy az eltérések határt szabjanak.
vagy akár követeli
Így P. L. Csebisev megmutatta a Bernoulli-tétel széles körű általánosításának lehetőségét. A. A. Markov tudomásul vette a további általánosítások lehetőségét, és javasolta a B. h név használatát. a Bernoulli-tétel általánosításainak teljes halmazára [és különösen a (3)-ra]. Csebisev módszere a matematika általános tulajdonságainak pontos megállapításán alapul. elvárásokról és az ún. Csebisev-egyenlőtlenségek[a (3) valószínűséghez az alak becslését adja meg
![]()
ez a határ természetesen pontosabbra cserélhető, jelentősebb megszorításokkal, lásd az ábrát. Bernstein-egyenlőtlenség].
A B. h. különféle formáinak utólagos bizonyítékai. bizonyos mértékig a Csebisev-módszer továbbfejlesztései. A valószínűségi változók megfelelő "redukcióját" alkalmazva (kicserélve azokat segédváltozókra, nevezetesen: , ha hol van néhány állandó), A. A. Markov kiterjesztette a B. ch. olyan esetekre, amikor a kifejezések eltérései nem léteznek. Például megmutatta, hogy (3) bizonyos konstansokra érvényes, ha ![]() és mindenki és
és mindenki és
1. rész – 9. FEJEZET A NAGY SZÁMOK TÖRVÉNYE. HATÁRTÉTELEK
Statisztikai definícióvalvalószínûsége, akkor a rendszer néhányként kezeli
a szám, amely felé a rokon
véletlenszerű esemény gyakorisága. Nál nél
a valószínűség axiomatikus meghatározása -
ez valójában a halmaz additív mértéke
esélyt előnyben részesítő eredmények
esemény. Az első esetben azzal van dolgunk
empirikus határ, a másodikban - -val
a mérték elméleti fogalma. Egyáltalán nem
Nyilvánvalóan ugyanarra utalnak
koncepció. Különböző definíciók kapcsolata
a valószínűségeket Bernoulli tétele határozza meg,
ami a nagy törvényének speciális esete
számok. A tesztek számának növekedésével
a binomiális törvény arra törekszik
normális eloszlás. Ez egy tétel
De Moivre-Laplace, ami az
a központi határ speciális esete
tételek. Az utóbbi azt mondja, hogy a függvény
független összegének eloszlása
növekvő számú valószínűségi változók
kifejezések általában normálisak
törvény.
A nagy számok törvénye és a központi
a határérték tétel alapszik
matematikai statisztika.
9.1. Csebisev egyenlőtlensége
Legyen a ξ valószínűségi változóvéges matematikai elvárás
M[ξ] és D[ξ] variancia. Aztán azért
tetszőleges ε pozitív szám
az egyenlőtlenség igaz:
Megjegyzések
Az ellenkező eseményhez:Csebisev egyenlőtlensége érvényes
bármilyen forgalmazási törvény.
Elhelyezés
tény:
, nem triviálist kapunk
9.2. A nagy számok törvénye Csebisev formában
Tétel Legyen valószínűségi változókpáronként függetlenek és végesek
az eltérések ugyanarra korlátozódnak
állandó
Aztán azért
Bármi
nekünk van
Így a nagy számok törvénye arról beszél
a valószínűségi változók számtani átlagának konvergenciája (azaz a valószínűségi változó)
számtani átlaguk mat. elvárások (pl.
nem véletlenszerű értékre).
9.2. A nagy számok törvénye Csebisev formában: Kiegészítés
Tétel (Markov): nagy törvényeszámok teljesülnek, ha a szórás
a valószínűségi változók összege nem nő
túl gyorsan, ahogy n nő:
10.9.3. Bernoulli tétele
Tétel: Tekintsük a Bernoulli-sémát.Legyen μn az A esemény előfordulásának száma in
n független próba, p az A esemény bekövetkezésének valószínűsége egyben
teszt. Aztán bármelyikhez
Azok. annak a valószínűsége, hogy az eltérés
től származó véletlenszerű esemény relatív gyakorisága
annak p valószínűsége tetszőlegesen modulo lesz
kicsi, a szám növekedésével egységbe hajlik.
tesztek n.
11.
Bizonyítás: μn véletlenszerű változóa binomiális törvény szerint elosztva, tehát
nekünk van
12.9.4. Jellegzetes funkciók
A véletlen karakterisztikus függvényea mennyiséget függvénynek nevezzük
ahol exp(x) = ex.
És így,
képviseli
egyesek elvárása
komplex valószínűségi változó
a nagyságrendhez kapcsolódik. Különösen, ha
egy diszkrét valószínűségi változó,
az eloszlássorozat (xi, pi) adja meg, ahol i
= 1, 2,..., n, akkor
13.
Folyamatos valószínűségi változóhozeloszlási sűrűséggel
valószínűségek
14.
15.9.5. Központi határérték tétel (Ljapunov-tétel)
16.
Megismételte a múltat17. A VALÓSZÍNŰSÉG ELMÉLETE ÉS A MATEMATIKAI STATISZTIKA ALAPJAI
RÉSZ II. MATEMATIKAISTATISZTIKA
18. Epigráf
"Háromféle hazugság van: hazugság,nyilvánvaló hazugságok és statisztikák"
Benjamin Disraeli
19. Bevezetés
A matematika két fő feladatastatisztika:
statisztikai adatok gyűjtése és csoportosítása
adat;
elemzési módszerek fejlesztése
attól függően kapott adatokat
kutatási célok.
20. Statisztikai adatelemzés módszerei:
egy esemény ismeretlen valószínűségének becslése;ismeretlen függvénybecslés
terjesztés;
az ismert paraméterek becslése
terjesztés;
a fajokkal kapcsolatos statisztikai hipotézisek igazolása
ismeretlen eloszlás ill
az ismert paraméterértékek
terjesztés.
21. FEJEZET 1. MATEMATIKAI STATISZTIKA ALAPFOGALMAI
22.1.1. Általános sokaság és minta
Általános lakosság – mindensok kutatott tárgy,
Minta - objektumok halmaza, véletlenszerűen
az általános populációból választották ki
kutatásra.
Az általános népesség volumene és
minta mérete - az objektumok száma az általános sokaságban és a mintában - megtesszük
N-ként, illetve n-ként jelöljük.
23.
A mintavétel megismétlődik, amikorminden kiválasztott objektum
a következő visszatérések kiválasztása
az általános lakosság, és
nem ismétlődő, ha kiválasztottuk
objektum az általános populációban
visszatér.
24. Reprezentatív minta:
megfelelően reprezentálja a jellemzőketáltalános lakosság, i.e. egy
képviselő (képviselő).
A nagy számok törvénye szerint azzal lehet érvelni
hogy ez a feltétel teljesül, ha:
1) az n mintaméret elég nagy;
2) a minta minden tárgyát véletlenszerűen választják ki;
3) minden objektumnál az elütés valószínűsége
a mintában ugyanaz.
25.
Általános sokaság és mintaegydimenziós lehet
(egytényezős)
és többdimenziós (többtényezős)
26.1.2. Mintaeloszlási törvény (statisztikai sorozat)
Engedjen be egy n méretű mintátszámunkra érdekes valószínűségi változó ξ
(az objektumok bármely paramétere
népesség) vesz n1
x1 értékének szorzata, n2 x2 értékének szorzata,... és
nk-szor az xk értéke. Aztán a megfigyelhető
egy valószínűségi változó x1, x2,..., xk értékei
ξ-ket változatoknak nevezzük, n1, n2,..., nk
– a frekvenciáikat.
27.
Az xmax – xmin különbség a tartományminták, az arány ωi = ni /n –
relatív frekvencia opciók xi.
Ez nyilvánvaló
28.
Ha a lehetőségeket növekvő sorrendben írjuk fel, akkor egy variációs sorozatot kapunk. Asztal, amelyből készültmegrendelt változata és azok gyakorisága
(és/vagy relatív gyakoriságok)
statisztikai sorozatnak nevezzük, ill
szelektív forgalmazás törvénye.
-- A diszkrét eloszlási törvényének analógja
valószínűségi változó a valószínűségelméletben
29.
Ha a variációs sorozat nagyonsok szám ill
néhány folyamatos
jel, használja csoportosítva
minta. Megszerzéséhez az intervallum
amely minden megfigyelhetőt tartalmaz
a jellemzőértékek fel vannak osztva
több általában egyenlő rész
h hosszúságú (részintervallumok). Nál nél
statisztikai sorozat összeállítása ben
mint xi, általában a felezőpontokat választják
részintervallumokat, és egyenlővé tegye az ni-t a számmal
változat, amely az i-edik részintervallumba esett.
30.
40- Frekvenciák -
35
30
n2
n3
ns
n1
25
20
15
10
5
0
a
a+h/2 a+3h/2
- Lehetőségek -
b-h/2
b
31.1.3. Frekvenciapoligon, mintaeloszlási függvény
Halasszuk el az xi valószínűségi változó értékeit ennyivelaz abszcissza tengely és az ni értékek az ordináta tengely mentén.
Szaggatott vonal, amelynek szegmensei összekapcsolódnak
pontok koordinátákkal (x1, n1), (x2, n2),..., (xk,
nk) sokszögnek nevezzük
frekvenciák. Ha ahelyett
abszolút értékek ni
tedd az y tengelyre
relatív frekvenciák ωi,
akkor relatív gyakoriságú sokszöget kapunk
32.
Az eloszlási függvénnyel analóg módondiszkrét valószínűségi változó által
az eloszlás mintavételi törvénye lehet
mintát készíteni (empirikus)
elosztási függvény
ahol az összesítést végrehajtják
frekvenciák, amelyek megfelelnek az értékeknek
változat, kisebb x. vegye észre, az
empirikus eloszlásfüggvény
az n mintanagyságtól függ.
33.
A funkcióval ellentétbenmegtalált
ξ valószínűségi változóhoz kísérleti
statisztikai adatok feldolgozásán keresztül a valódi funkció
terjesztés
társult, összekapcsolt, társított valamivel
az általános populációt nevezik
elméleti. (általában általános
az aggregátum olyan nagy, hogy
lehetetlen mindezt feldolgozni;
csak felfedezni lehet
elméletben).
34.
Figyeld meg, hogy:35.1.4. Az empirikus eloszlásfüggvény tulajdonságai
lépettKilátás
36.
Egy másik grafikus ábrázolása minta, amelyre kíváncsiak vagyunk
hisztogram - lépcsős ábra,
téglalapokból áll, amelyek alapjai részintervallumok
szélesség h és magasságok - hosszúságú szegmensek
ni/h (frekvencia hisztogram) vagy ωi/h
(relatív gyakoriságok hisztogramja).
Az első esetben
hisztogram területe megegyezik a térfogattal
minták n, közben
második - egység
37. Példa
38. 2. FEJEZET A MINTA NUMERIKUS JELLEMZŐI
39.
A matematikai statisztika feladata azszerezzen be a rendelkezésre álló mintából
információk az általánosról
aggregátumok. Reprezentatív minta számszerű jellemzői - a releváns jellemzők értékelése
vizsgált valószínűségi változó,
általánoshoz kapcsolódik
összesített.
40.2.1. Mintaátlag és minta szórása, tapasztalati momentumok
A minta átlagát únértékek számtani átlaga
változat a mintában
A minta átlagát használjuk
matematikai statisztikai értékelése
a vizsgált valószínűségi változóval kapcsolatos elvárások.
41.
A minta variancia únértéke egyenlő
Minta középnégyzet
eltérés -
42.
Könnyű megmutatni, hogy mi történika következő összefüggés, kényelmes
variancia számítás:
43.
Egyéb jellemzőkvariációs sorozatok a következők:
Az M0 mód egy változata, amelynek
a legmagasabb frekvencia, és a medián me
variációt osztó változat
sorszámmal egyenlő két részre
választási lehetőség.
2, 5, 2, 11, 5, 6, 3, 13, 5 (mód = 5)
2, 2, 3, 5, 5, 5, 6, 11,13 (medián = 5)
44.
A megfelelővel analógiávalelméleti kifejezéseket lehet
empirikus pillanatokat építeni,
statisztikai célokra használják
értékelések elsődleges és központi
a véletlen pillanatai
mennyiségeket.
45.
A pillanatokkal analógiávalelméletek
valószínűségek kezdeti empirikus módszerrel
rendelés pillanata m a mennyiség
központi empirikus pont
rendelés m -
46.2.2. Az eloszlási paraméterek statisztikai becslésének tulajdonságai: torzítatlanság, hatékonyság, konzisztencia
2.2. A statisztikai becslések tulajdonságaieloszlási paraméterek: elfogulatlanság, hatékonyság, konzisztencia
Statisztikai becslések kézhezvétele után
véletlenszerű eloszlási paraméterek
ξ értékek: minta átlaga, minta szórása stb., erről meg kell győződnie
hogy jó közelítést jelentenek
a releváns paraméterekhez
elméleti eloszlás ξ.
Keressük meg a feltételeket, amelyek ehhez szükségesek
végre kell hajtani.
47.
48.
Az A* statisztikai pontszámot nevezzükelfogulatlan, ha matematikai
elvárás egyenlő a kiértékelt paraméterrel
általános népesség A bármely
mintanagyság, pl.
Ha ez a feltétel nem teljesül, a becslés
offszetnek nevezzük.
Az elfogulatlan becslés nem elegendő
feltétele a statisztika jó közelítésének
A* pontszámot ad a valódi (elméleti) értékre
becsült A paraméter.
49.
Az egyéni értékek szórásaaz M átlagértékhez képest
a D szórástól függ.
Ha a szórás nagy, akkor az érték
egy minta adataiból kiderült,
jelentősen eltérhet ettől
értékelt paraméter.
Ezért a megbízható
becslési variancia D kell
legyen kicsi. Statisztikai értékelés
hatékonynak nevezzük, ha
adott n-es mintamérettel rendelkezik
lehető legkisebb szórás.
50.
A statisztikai becslésekhezmég mindig követelmény
életképességét. A pontszámot hívják
konzisztens if as n → it
hajlamos arra, hogy
paraméter értékelés alatt áll. vegye észre, az
az elfogulatlan becslés az lesz
konzisztens ha as n → annak
a szórás 0-ra hajlamos.
51. 2.3. Minta átlagos tulajdonságok
Feltételezzük, hogy az x1, x2,..., xn opcióka megfelelő értékei
független, azonos eloszlású valószínűségi változók
,
matematikai elvárásokkal
és diszperzió
. Azután
a mintaátlag lehet
valószínűségi változóként kezeljük
52.
Elfogulatlan. Az ingatlanokbóla matematikai elvárás arra utal
azok. a minta átlaga az
a matematikai elfogulatlan becslése
valószínűségi változó elvárása.
Megmutathatja a hatékonyságot is
becslések a matematikai várakozás mintaátlaga alapján (normál esetén
terjesztés)
53.
Következetesség. Legyen a a becsült értékparaméter, nevezetesen a matematikai
lakossági elvárás
– populációs variancia
.
Tekintsük a Csebisev-egyenlőtlenséget
Nekünk van:
azután
. Ahogy n → jobb oldal
az egyenlőtlenség nullára hajlik minden ε > 0 esetén, azaz
és innen a mintát képviselő X érték
a becslés a valószínűség szempontjából a becsült a paraméterre hajlik.
54.
Így arra lehet következtetnihogy a mintaátlag az
elfogulatlan, hatékony (szerint
legalábbis normálisnak
eloszlás) és következetes
várható becslés
-hoz társított valószínűségi változó
az általános lakosság.
55.
56.
6. ELŐADÁS57. 2.4. Minta variancia tulajdonságai
Megvizsgáljuk a D* as minta variancia torzítatlanságátvalószínűségi változó varianciájának becslései
58.
59.
60. Példa
Minta átlag, minta keresésevariancia és a négyzetgyök
eltérés, mód és korrigált minta
szórás a következőkkel rendelkező minta esetén
elosztási törvény:
Döntés:
61.
62. FEJEZET 3. AZ ISMERT ELOSZTÁS PARAMÉTEREINEK PONTBECSLÉSE
63.
Feltételezzük, hogy a törvény általános formájaterjesztése ismert számunkra és
hátra van a részletek tisztázása -
paraméterek, amelyek meghatározzák
tényleges formája. Létezik
ennek megoldására több módszer
feladatok, amelyek közül kettőt mi
fontolja meg: a pillanatok módszere és a módszer
a legnagyobb valószínűség
64.3.1. A pillanatok módszere
65.
A pillanatok módszere, amelyet Carl fejlesztett kiPearson 1894-ben, alapján
ezeket a közelítő egyenlőségeket használva:
pillanatok
számított
elméletileg az ismert törvény szerint
θ paraméterű eloszlások, és
minta pillanatok
számított
a rendelkezésre álló minta szerint. Ismeretlen
lehetőségek
-ban meghatározott
r egyenletrendszer megoldásának eredménye,
releváns linkelés
elméleti és empirikus pillanatok,
Például,
.
66.
Kimutatható, hogy a becslésekmódszerrel kapott θ paraméterek
pillanatok, gazdagok, az övék
a matematikai elvárások mások
a paraméterek valódi értékétől a
n–1 nagyságrendű értéke, és az átlag
szórások vannak
n-0,5 nagyságrendű értékek
67. Példa
Ismeretes, hogy az objektumok jellemző ξaz általános populáció, mivel véletlenszerű
érték, egyenletes eloszlású az a és b paraméterek függvényében:
A pillanatok módszerével kell meghatározni
a és b paraméterek ismert minta szerint
átlagos
és a minta variancia
68. Emlékeztető
α1 - matematikai elvárás β2 - variancia69.
(*)70.
71.3.2. Maximális valószínűség módszere
A módszer a likelihood függvényen alapulL(x1, x2,..., xn, θ), ami a törvény
vektoreloszlások
, ahol
Véletlen változók
értékeket vesz fel
mintavételi lehetőség, i.e. ugyanaz legyen
terjesztés. Mivel a valószínűségi változók
függetlenek, a valószínűségfüggvény alakja a következő:
72.
A legnagyobb módszerének ötletea hihetőség abban rejlik, hogy mi
a θ paraméterek ilyen értékeit keressük, at
amelyben az előfordulás valószínűsége
értékválasztás x1, x2,..., xn változat
a legnagyobb. Más szavakkal,
a θ paraméterek becsléseként
olyan vektort veszünk fel, amelyre a függvény
valószínűsége van egy helyi
maximum adott x1, x2, …, xn esetén:
73.
Becslések a maximum módszerévela hihetőséget abból nyerjük
szükséges extrém állapot
L(x1,x2,..., xn,θ) függvények egy pontban
74. Megjegyzések:
1. Amikor a likelihood függvény maximumát keresia számítások egyszerűsítése érdekében elvégezheti
olyan műveletek, amelyek nem változtatják meg az eredményt: először
L(x1, x2,..., xn,θ) helyett használja a logaritmikus likelihood függvényt l(x1, x2,..., xn,θ) =
log L(x1, x2,..., xn,θ); másodszor, dobja el a kifejezésben
a θ-től független valószínűségfüggvényre
kifejezések (l-re) vagy pozitív
tényezők (L-re).
2. Az általunk figyelembe vett paraméterbecslések a következők
pontbecslésnek nevezhető, hiszen a számára
ismeretlen paraméter θ, egy
egyetlen pont
, ami az övé
hozzávetőleges érték. Ez a megközelítés azonban
durva hibákhoz vezethet, és pont
értékelése jelentősen eltérhet a valóditól
a becsült paraméter értékei (különösen a
kis mintanagyság).
75. Példa
Döntés. Ebben a feladatban értékelni kellkét ismeretlen paraméter: a és σ2.
Log-likelihood függvény
van formája
76.
A kifejezés elvetése ebben a képletben, ami nema-tól és σ2-től függ, összeállítjuk az egyenletrendszert
hitelesség
Megoldva a következőket kapjuk:
77. 4. FEJEZET AZ ISMERT ELOSZTÁS PARAMÉTERÉNEK INTERVALLUMBECSLÉSE
78.
(*)
79.
(*)80.4.1. Egy ismert szórással rendelkező, normális eloszlású mennyiség matematikai elvárásának becslése
minta átlag
véletlenszerű értékként
81.
Nekünk van:(1)
(2)
82.
(2)(1)
(*)
(*)
83.4.2. Ismeretlen varianciájú, normális eloszlású mennyiség matematikai elvárásának becslése
84.
szabadsági fokokat. Sűrűség
mennyiségek vannak
85.
86. Student sűrűségeloszlás n - 1 szabadságfokkal
87.
88.
89.
képletekkel keresse meg
90. 4.3. Normális eloszlású mennyiség szórásának becslése
eltérés σ.
ismeretlen matematikai
várakozás.
91. 4.3.1. A jól ismert matematikai elvárás speciális esete
A mennyiségek felhasználásával
,
minta eltérés D*:
92.
mennyiségeket
normális legyen
93.
körülmények
ahol
az eloszlási sűrűség χ2
94.
95.
96.
97.4.3.2. Az ismeretlen matematikai elvárás speciális esete
(ahol a valószínűségi változó
χ2 n–1 szabadságfokkal.
98.
99.4.4. Valószínűségi változó matematikai elvárásainak becslése tetszőleges mintára
nagy minta (n >> 1).
100.
mennyiségeket
amelynek
diszperzió
, és a kapott
minta átlag
értékként
valószínűségi változó
nagyságrendű
aszimptotikusan rendelkezik
.
101.
használja a képletet
102.
103.
7. előadás104.
A múlt ismétlése105. FEJEZET 4. AZ ISMERETT ELOSZTÁS PARAMÉTEREINEK INTERVALLUM BECSLÉSE
106.
Egy ismert paraméter becslésének problémájaaz eloszlásokat úgy lehet megoldani
intervallum felépítése, amelyben adottval
valós értéke valószínű
paraméter. Ez az értékelési módszer
intervallumbecslésnek nevezzük.
Általában a matematikában az értékeléshez
θ paraméterrel megszerkesztjük az egyenlőtlenséget
(*)
ahol a δ szám a becslés pontosságát jellemzi:
minél kisebb δ, annál jobb a becslés.
107.
(*)108.4.1. Egy ismert szórással rendelkező, normális eloszlású mennyiség matematikai elvárásának becslése
Legyen a vizsgált ξ valószínűségi változó eloszlása a normáltörvény szerint ismertekkelszórás σ és
ismeretlen matematikai elvárás a.
A mintaátlag értéke megköveteli
becsüljük meg a ξ matematikai elvárást.
Mint korábban, most is figyelembe vesszük az eredményt
minta átlag
véletlenszerű értékként
értékek, az értékek pedig a mintaváltozat x1, x2, …,
xn - rendre, mivel az értékek megegyeznek
elosztott független valószínűségi változók
, amelyek mindegyikéhez tartozik egy szőnyeg. a elvárás és a szórás σ.
109.
Nekünk van:(1)
(2)
110.
(2)(1)
(*)
(*)
111.4.2. Ismeretlen varianciájú, normális eloszlású mennyiség matematikai elvárásának becslése
112.
Ismeretes, hogy a tn valószínűségi változó,ily módon adott
Student-féle eloszlás, ahol k = n - 1
szabadsági fokokat. Sűrűség
az ilyenek valószínűségi eloszlása
mennyiségek vannak
113.
114. Student sűrűségeloszlás n - 1 szabadságfokkal
115.
116.
117.
Jegyzet. Sok fokszámmalszabadság k Hallgatói eloszlás
-val normál eloszlásra hajlamos
nulla matematikai elvárás és
egyetlen variancia. Ezért k ≥ 30 esetén
konfidencia intervallum lehet a gyakorlatban
képletekkel keresse meg
118. 4.3. Normális eloszlású mennyiség szórásának becslése
Legyen a vizsgált valószínűségi változóξ a normáltörvény szerint oszlik el
elvárással a és
ismeretlen középnégyzet
eltérés σ.
Tekintsünk két esetet: ismert és
ismeretlen matematikai
várakozás.
119. 4.3.1. A jól ismert matematikai elvárás speciális esete
Legyen ismert az M[ξ] = a érték éscsak σ-t vagy a D[ξ] = σ2 varianciát értékeljük ki.
Emlékezzünk rá egy ismert szőnyegre. várakozás
a variancia torzítatlan becslése az
minta variancia D* = (σ*)2
A mennyiségek felhasználásával
,
fent definiált, bevezetünk egy véletlen
Y érték, amely az értékeket veszi fel
minta eltérés D*:
120.
Tekintsünk egy valószínűségi változótA jel alatti összegek véletlenszerűek
mennyiségeket
normális legyen
eloszlás fN sűrűséggel (x, 0, 1).
Ekkor Hn-nek χ2 eloszlása van n-nel
szabadsági fokok az n négyzetek összegeként
független szabvány (a = 0, σ = 1)
normál valószínűségi változók.
121.
Határozzuk meg a konfidencia intervallumot innenkörülmények
ahol
az eloszlási sűrűség χ2
és γ - megbízhatóság (megbízhatóság
valószínűség). γ értéke számszerűen egyenlő
ábrán látható árnyékolt ábra területe.
122.
123.
124.
125. 4.3.2. Az ismeretlen matematikai elvárás speciális esete
A gyakorlatban a leggyakoribb helyzetamikor a normál mindkét paramétere ismeretlen
eloszlások: matematikai elvárás a és
szórás σ.
Ebben az esetben bizalomépítés
intervallum Fisher tételén alapul, től
macska. ebből következik, hogy a valószínűségi változó
(ahol a valószínűségi változó
az elfogulatlan értékeket véve
az s2 mintavarianciának eloszlása van
χ2 n–1 szabadságfokkal.
126.
127.4.4. Valószínűségi változó matematikai elvárásainak becslése tetszőleges mintára
A matematikai intervallumbecslésekelvárások M[ξ] normál esetben kapott
elosztott valószínűségi változó ξ ,
általában alkalmatlanok
különböző formájú valószínűségi változók
terjesztés. Van azonban olyan helyzet, amikor
bármely valószínűségi változóhoz
hasonló intervallumokat használjon
kapcsolatok, ez történik
nagy minta (n >> 1).
128.
Mint fent, megfontoljuk a lehetőségeketx1, x2,..., xn független értékek,
egyenlő eloszlású véletlenszerű
mennyiségeket
amelynek
elvárás M[ξi] = mξ és
diszperzió
, és a kapott
minta átlag
értékként
valószínűségi változó
A centrális határértéktétel szerint
nagyságrendű
aszimptotikusan rendelkezik
normál elosztási törvény c
elvárás mξ és szórás
.
129.
Ezért ha ismert a variancia értékeξ valószínűségi változót, akkor tudjuk
közelítő képleteket használjon
Ha a mennyiség szórásának értéke ξ
ismeretlen, akkor nagy n lehet
használja a képletet
ahol s a korrigált effektív érték. eltérés
130.
Megismételte a múltat131. FEJEZET 5. STATISZTIKAI HIPOTÉZISEK ELLENŐRZÉSE
132.
A statisztikai hipotézis egy hipotézis arrólegy ismeretlen eloszlás formája vagy a paraméterekről
egy valószínűségi változó ismert eloszlása.
A tesztelendő hipotézis, általában jelöléssel
H0-t null- vagy főhipotézisnek nevezzük.
A kiegészítőleg használt H1 hipotézis,
a H0 hipotézisnek ellentmondó ún
versengő vagy alternatív.
A fejlett null statisztikai ellenőrzése
A H0 hipotézis összevetéséből áll
minta adat. Ilyen csekkel
Kétféle hiba fordulhat elő:
a) az első típusú hibák - azok az esetek, amikor elutasítják
helyes hipotézis H0;
b) a második típusú hibák – olyan esetek, amikor
a hibás H0 hipotézist elfogadjuk.
133.
Az első típusú hiba valószínűsége a következő leszhívja meg a szignifikancia szintet és jelölje ki
mint a.
A statisztikai ellenőrzés fő technikája
a hipotézis az
rendelkezésre álló minta, az érték kiszámítása megtörténik
statisztikai kritérium - néhány
ismert T valószínűségi változó
elosztási törvény. T értéktartomány,
amely alatt a H0 főhipotézisnek kell
elutasítják, kritikusnak nevezik, és
T értéktartomány, amelyre ez a hipotézis vonatkozik
átvehető, - átvételi terület
hipotéziseket.
134.
135.5.1. Hipotézisek tesztelése egy ismert eloszlás paramétereiről
5.1.1. Hipotézisvizsgálat a matematikárólnormális eloszlású véletlen elvárása
mennyiségeket
Legyen a ξ valószínűségi változó
normális eloszlás.
Ellenőriznünk kell azt a feltételezést
hogy annak matematikai elvárása az
valami a0 szám. Fontolja meg külön
olyan esetekben, amikor a ξ variancia ismert és mikor
ő ismeretlen.
136.
Ismert diszperzió esetén D[ξ] = σ2,a 4.1. §-ban leírtak szerint véletlenszerűséget definiálunk
olyan érték, amely felveszi az értékeket
minta átlag. H0 hipotézis
kezdetben M[ξ] =ként fogalmazódott meg
a0. Mivel a minta átlaga
akkor M[ξ] torzítatlan becslése
a H0 hipotézist úgy ábrázolhatjuk
137.
Figyelembe véve a javított elfogulatlanságátmintavarianciák, a nullhipotézis lehet
így írd le:
ahol valószínűségi változó
felveszi a korrigált minta értékeit
ξ diszperziója és hasonló a véletlenhez
a 4.2. pontban figyelembe vett Z értéke.
Statisztikai kritériumként azt választjuk
valószínűségi változó
a nagyobb arányának értékét véve
minta variancia egy kisebbre.
145.
Az F véletlenváltozónak vanFisher-Snedecor disztribúcióval
a szabadságfokok száma k1 = n1 – 1 és k2
= n2 – 1, ahol n1 a minta mérete, aszerint
amely a nagyobb
korrigált variancia
, és n2
a második minta térfogata, amelyhez
kisebb eltérést talált.
Vegye figyelembe a versengés két típusát
hipotéziseket
146.
147.
148. 5.1.3. Független valószínűségi változókra vonatkozó matematikai elvárások összehasonlítása
Nézzük először a normális esetétismertekkel való valószínűségi változók eloszlásai
eltérések, majd ez alapján - egy általánosabb
mennyiségek önkényes elosztásának esete at
elég nagy független minták.
Legyenek a ξ1 és ξ2 valószínűségi változók függetlenek és
normális eloszlásúak, és legyen eltérésük D[ξ1]
és D[ξ2] ismert. (Például megtalálhatóak
valamilyen más tapasztalatból vagy számított
elméletben). Kivont n1 és n2 méretű minták
illetőleg. Legyen
– szelektív
átlagok ezekre a mintákra. Szükséges szelektív
átlag egy adott α szignifikanciaszinten
tesztelje a matematikai egyenlőségre vonatkozó hipotézist
a számításba vett valószínűségi változókkal kapcsolatos elvárások a priori megfontolások alapján,
kísérleti körülmények alapján, és
majd a paraméterekkel kapcsolatos feltételezéseket
az eloszlásokat a képen látható módon vizsgáljuk
korábban. Azonban nagyon gyakran van
ellenőrizni kell a
hipotézis az eloszlás törvényéről.
Statisztikai teszteket terveztek
az ilyen ellenőrzésekre általában ún
beleegyezési kritériumok.
154.
Az egyetértésnek több kritériuma ismert. MéltóságPearson kritériuma az egyetemesség. Ezzel
különböző hipotézisek tesztelésére használható
elosztási törvények.
A Pearson-kritérium a frekvenciák összehasonlításán alapul,
a mintából talált (empirikus gyakoriságok), s
a tesztelt felhasználásával számított gyakoriságok
eloszlási törvény (elméleti frekvenciák).
Általában empirikus és elméleti frekvenciák
különbözik. Ki kell derítenünk, hogy ez véletlen-e
gyakorisági eltérés, vagy ez jelentős és magyarázható
az a tény, hogy az elméleti gyakoriságokat ez alapján számítják ki
hibás hipotézis az általános eloszlásáról
aggregátumok.
A Pearson-kritérium, mint bármely más, megválaszolja a
A kérdés az, hogy van-e egyetértés a javasolt hipotézis és
empirikus adatok adott szinten
jelentőség.
155. 5.2.1. A normál eloszlás hipotézisének tesztelése
Legyen egy ξ valószínűségi változó és legyenegy kellően nagy méretű n minta egy nagy
különböző értékek száma opció. Kívánt
α szignifikancia szinten tesztelje a nullhipotézist
H0 hogy a ξ valószínűségi változó eloszlik
bírság.
A minta feldolgozásának kényelme érdekében két számot veszünk
α és β:
és osszuk el az [α, β] intervallumot s-vel
részintervallumok. Feltételezzük, hogy a változat értékei,
az egyes részintervallumokba eső értékek megközelítőleg egyenlőek
egy szám, amely az alintervallum közepét adja meg.
Az egyes α (0.) sorrendű kvantilisekbe eső opciók számának megszámolása< α < 1) непрерывной
a ξ valószínűségi változó egy olyan xα szám,
amelyre az egyenlőség
.
Az x½ kvantilist a véletlen mediánjának nevezzük
a ξ mennyiségek, az x0 és x2 kvantilisek a kvartilisei, a
x0,1, x0,2,..., x0,9 - decilis.
A standard normál eloszláshoz (a =
0, σ = 1), és ezért
ahol FN (x, a, σ) a normális eloszlási függvény
elosztott valószínűségi változó, és Φ(x)
Laplace függvény.
A standard normál eloszlás kvantiliseje
xα adott α-ra a relációból megtalálható
162.6.2. Hallgatói elosztás
Ha egy- független
valószínűségi változók, amelyek
normál eloszlás nullával
matematikai elvárás és
egységnyi szórás, akkor
valószínűségi változó eloszlás
az úgynevezett Student-féle t-eloszlás
n szabadságfokkal (W.S. Gosset).
A nagy számok törvénye a valószínűségszámításban azt állítja, hogy egy fix eloszlásból származó kellően nagy véges minta tapasztalati átlaga (számtani átlaga) közel van ennek az eloszlásnak az elméleti átlagához (várakozáshoz). A konvergencia típusától függően megkülönböztetjük a nagy számok gyenge törvényét, amikor a valószínűség konvergenciája van, és a nagy számok erős törvényét, amikor szinte mindenhol konvergencia van.
Mindig van véges számú kísérlet, amelyre adott valószínűséggel kisebb, mint 1 valamely esemény relatív előfordulási gyakorisága tetszőlegesen kevéssé fog eltérni annak valószínűségétől.
A nagy számok törvényének általános jelentése: nagyszámú azonos és független véletlentényező együttes hatása olyan eredményhez vezet, amely határértékben nem a véletlentől függ.
A véges minta elemzésén alapuló valószínűségbecslési módszerek ezen a tulajdonságon alapulnak. Jó példa erre a választási eredmények előrejelzése választói mintán végzett felmérés alapján.
Enciklopédiai YouTube
1 / 5
✪ A nagy számok törvénye
✪ 07 – Valószínűségszámítás. A nagy számok törvénye
✪ 42 A nagy számok törvénye
✪ 1 – Csebisev nagy számok törvénye
✪ 11. évfolyam, 25. lecke, Gauss-görbe. A nagy számok törvénye
Feliratok
Vessünk egy pillantást a nagy számok törvényére, amely talán a legintuitívabb törvény a matematikában és a valószínűségszámításban. És mivel nagyon sok mindenre vonatkozik, néha használják és félreértik. Hadd adjak meg először egy definíciót a pontosság szempontjából, aztán beszélünk az intuícióról. Vegyünk egy valószínűségi változót, mondjuk X. Tegyük fel, hogy ismerjük a matematikai elvárásait vagy a populációs átlagát. A nagy számok törvénye egyszerűen azt mondja, hogy ha egy valószínűségi változó n-edik számú megfigyelésének példáját vesszük, és ezeknek a megfigyeléseknek a számát átlagoljuk... Vegyünk egy változót. Nevezzük X-nek n alsó indexszel és kötőjellel a tetején. Ez a valószínűségi változónk n-edik számú megfigyelésének számtani átlaga. Íme az első megfigyelésem. Egyszer megcsinálom a kísérletet, és megteszem ezt a megfigyelést, majd újra megcsinálom és ezt a megfigyelést, újra megcsinálom és ezt kapom. Ezt a kísérletet n-szer lefuttatom, majd elosztom a megfigyeléseim számával. Itt van a mintaátlagom. Itt van az általam végzett összes megfigyelés átlaga. A nagy számok törvénye azt mondja, hogy a minta átlaga közelíti a valószínűségi változó átlagát. Vagy azt is leírhatom, hogy a mintaátlagom megközelíti a végtelenbe tartó n-edik szám populációs átlagát. Nem teszek egyértelmű különbséget a "közelítés" és a "konvergencia" között, de remélem, intuitívan megértitek, hogy ha itt elég nagy mintát veszek, akkor a populáció egészére nézve megkapom a várható értéket. Azt hiszem, a legtöbben intuitív módon megértik, hogy ha elég sok tesztet végzek el sok példával, akkor végül a tesztek azt az értékeket fogják megadni, amelyeket elvárok, figyelembe véve a matematikai elvárásokat, valószínűségeket és minden mást. De azt hiszem, gyakran nem világos, miért történik ez. És mielőtt elkezdeném elmagyarázni, miért van ez így, hadd mondjak egy konkrét példát. A nagy számok törvénye azt mondja, hogy... Tegyük fel, hogy van egy X valószínűségi változó. Ez egyenlő a fejek számával a helyes érme 100 feldobásakor. Először is ismerjük ennek a valószínűségi változónak a matematikai elvárását. Ez az érmefeldobások vagy próbálkozások száma szorozva a próba sikerének esélyével. Tehát egyenlő 50-nel. Vagyis a nagy számok törvénye azt mondja, hogy ha mintát veszünk, vagy ha átlagolom ezeket a próbákat, akkor megkapom. .. Amikor először csinálok tesztet, feldobok egy érmét 100-szor, vagy veszek egy doboz száz érmét, megrázom, majd megszámolom, hány fejet kapok, és megkapom mondjuk az 55-ös számot. X1. Aztán újra megrázom a dobozt, és a 65-ös számot kapom. Aztán megint - és 45-öt kapok. És ezt n-szer megcsinálom, majd elosztom a próbálkozások számával. A nagy számok törvénye azt mondja nekünk, hogy ez az átlag (az összes megfigyelésem átlaga) 50-re, míg n a végtelenre hajlik. Most egy kicsit arról szeretnék beszélni, hogy miért történik ez. Sokan úgy gondolják, hogy ha 100 próba után átlagon felüli az eredményem, akkor a valószínűség törvényei szerint több-kevesebb fejnek kell lennie ahhoz, hogy úgymond kompenzáljam a különbséget. Nem pontosan ez fog történni. Ezt gyakran „szerencsejátékos tévedésnek” nevezik. Hadd mutassam meg a különbséget. A következő példát fogom használni. Hadd rajzoljak egy grafikont. Változtassuk meg a színt. Ez n, az én x tengelyem n. Ennyi tesztet fogok futtatni. És az én y tengelyem lesz a minta átlaga. Tudjuk, hogy ennek a tetszőleges változónak az átlaga 50. Hadd rajzoljam ezt le. Ez 50. Térjünk vissza példánkhoz. Ha n... Az első tesztem során 55-öt kaptam, ami az átlagom. Csak egy adatbeviteli pontom van. Aztán két próba után 65-öt kapok. Tehát az átlagom 65+55 osztva 2-vel. Ez 60. És az átlagom emelkedett egy kicsit. Aztán 45-öt kaptam, ami megint csökkentette a számtani átlagomat. Nem fogok 45-öt ábrázolni a diagramon, most az egészet átlagolnom kell. Mit jelent 45+65? Hadd számítsam ki ezt az értéket a pont ábrázolásához. Ez 165 osztva 3-mal. Ez 53. Nem, 55. Tehát az átlag ismét 55-re csökken. Folytathatjuk ezeket a teszteket. Miután elvégeztünk három próbát, és ezt az átlagot kihoztuk, sokan azt gondolják, hogy a valószínűség istenei megcsinálják, hogy a jövőben kevesebb lesz a fejünk, hogy a következő néhány próba alacsonyabb lesz az átlag csökkentése érdekében. De ez nem mindig van így. A jövőben a valószínűség mindig ugyanaz marad. Annak a valószínűsége, hogy fejet fogok dobni, mindig 50%. Nem mintha először kapok egy bizonyos számú fejet, többet, mint amennyit várok, aztán hirtelen farok esik ki. Ez a "játékos tévedése". Ha aránytalanul sok fejet kap, az nem jelenti azt, hogy egy ponton aránytalanul sok farok kezd kihullani. Ez nem teljesen igaz. A nagy számok törvénye azt mondja, hogy ez nem számít. Mondjuk, bizonyos véges számú próba után az átlagod... Ennek elég kicsi a valószínűsége, de ennek ellenére... Tegyük fel, hogy az átlagod eléri ezt a 70-et. Azt gondolod: "Hűha, jóval túlléptük a várakozásokat." De a nagy számok törvénye szerint nem mindegy, hány tesztet futtatunk le. Még mindig végtelen számú próba vár ránk. Ennek a végtelen számú próbának a matematikai elvárása, különösen hasonló helyzetben, a következő lesz. Ha olyan véges számhoz jutunk, amely valamilyen nagy értéket fejez ki, egy végtelen szám, amely konvergál vele, ismét a várt értékhez vezet. Ez persze nagyon laza értelmezés, de ezt mondja nekünk a nagy számok törvénye. Fontos. Azt nem mondja, hogy ha sok fejet kapunk, akkor valahogy megnő az esélye annak, hogy farkokat kapjunk, hogy ezt kompenzálja. Ez a törvény azt mondja nekünk, hogy mindegy, hogy véges számú próbával mi lesz az eredmény, mindaddig, amíg még végtelen számú próba áll előtted. És ha eleget készítesz belőlük, ismét visszatérsz a várthoz. Ez egy fontos szempont. Gondolkozz el róla. De ezt a gyakorlatban nem használják naponta a lottóknál, kaszinóknál, pedig köztudott, hogy ha elég tesztet csinálsz... Akár ki is számolhatjuk... mennyi a valószínűsége, hogy komolyan eltérünk a normától? De a kaszinók és a lottó minden nap azon az elven működnek, hogy ha elég embert viszel el, persze rövid időn belül, kis mintával, akkor páran megütik a főnyereményt. De hosszú távon a kaszinó mindig hasznot húz azon játékok paramétereiből, amelyekre meghívják Önt. Ez egy fontos valószínűségi elv, amely intuitív. Bár néha, amikor ezt formálisan véletlenszerű változókkal magyarázzák el, mindez kissé zavarónak tűnik. Ez a törvény csak annyit mond, hogy minél több minta van, annál inkább konvergál ezeknek a mintáknak a számtani átlaga a valódi átlaghoz. És hogy pontosabbak legyünk, a minta számtani középértéke konvergál egy valószínűségi változó matematikai elvárásával. Ez minden. Találkozunk a következő videóban!
A nagy számok gyenge törvénye
A nagy számok gyenge törvényét Bernoulli tételének is nevezik Jacob Bernoulli után, aki 1713-ban bebizonyította.
Legyen egy végtelen sorozat (egymást követő felsorolás) azonos eloszlású és korrelálatlan valószínűségi változókból. Vagyis a kovarianciájuk c o v (X i , X j) = 0, ∀ i ≠ j (\displaystyle \mathrm (cov) (X_(i),X_(j))=0,\;\forall i\not =j). Legyen . Jelölje az első mintaátlagával n (\displaystyle n) tagok:
.
Azután X ¯ n → P μ (\displaystyle (\bar (X))_(n)\to ^(\!\!\!\!\!\!\mathbb (P) )\mu ).
Vagyis minden pozitívumra ε (\displaystyle \varepsilon )
lim n → ∞ Pr (| X ¯ n − μ |< ε) = 1. {\displaystyle \lim _{n\to \infty }\Pr \!\left(\,|{\bar {X}}_{n}-\mu |<\varepsilon \,\right)=1.}A nagy számok erős törvénye
Legyen független azonos eloszlású valószínűségi változók végtelen sorozata ( X i ) i = 1 ∞ (\displaystyle \(X_(i)\)_(i=1)^(\infty )) egy valószínűségi téren van meghatározva (Ω , F , P) (\displaystyle (\Omega ,(\mathcal (F)),\mathbb (P))). Legyen E X i = μ , ∀ i ∈ N (\displaystyle \mathbb (E) X_(i)=\mu ,\;\all i\in \mathbb (N) ). Jelölje X¯n (\displaystyle (\bar(X))_(n)) az első mintaátlaga n (\displaystyle n) tagok:
X ¯ n = 1 n ∑ i = 1 n X i , n ∈ N (\displaystyle (\bar (X))_(n)=(\frac (1)(n))\sum \limits _(i= 1)^(n)X_(i),\;n\in \mathbb (N) ).Azután X ¯ n → μ (\displaystyle (\bar (X))_(n)\to \mu ) szinte mindig.
Pr (lim n → ∞ X ¯ n = μ) = 1. (\displaystyle \Pr \!\left(\lim _(n\to \infty )(\bar (X))_(n)=\mu \ jobb)=1.) .Mint minden matematikai törvény, a nagy számok törvénye is csak ismert feltevések mellett alkalmazható a való világra, amely csak bizonyos fokú pontossággal teljesíthető. Így például az egymást követő tesztek feltételei gyakran nem tarthatók fenn a végtelenségig és abszolút pontossággal. Ráadásul a nagy számok törvénye csak arról beszél valószínűtlenség az átlagérték szignifikáns eltérése a matematikai elvárástól.
A nagy számokra vonatkozó szavak a tesztek számára utalnak - egy valószínűségi változó nagyszámú értékét vagy nagyszámú valószínűségi változó kumulatív hatását vesszük figyelembe. Ennek a törvénynek a lényege a következő: bár lehetetlen megjósolni, hogy egyetlen valószínűségi változó mekkora értéket vesz fel egyetlen kísérletben, azonban nagyszámú független valószínűségi változó hatásának összesített eredménye elveszti véletlenszerű jellegét, és szinte megbízhatóan (azaz nagy valószínűséggel) előre jelezhető. Például lehetetlen megjósolni, hogy az érme melyik oldalára esik. Ha azonban 2 tonna érmét dob fel, akkor nagy bizalommal lehet vitatkozni, hogy a címerrel felfelé hullott érmék súlya 1 tonna.
Mindenekelőtt az úgynevezett Csebisev-egyenlőtlenség a nagy számok törvényére utal, amely egy külön tesztben becsüli meg, hogy egy olyan valószínűségi változó milyen valószínűséggel fogad el egy értéket, amely legfeljebb egy adott értékkel tér el az átlagos értéktől.
Csebisev egyenlőtlensége. Legyen x egy tetszőleges valószínűségi változó, a=M(X) , a D(x) a diszperziója. Azután
Példa. A gépen megmunkált hüvely átmérőjének névleges (azaz szükséges) értéke a 5 mm, és a szórás nincs többé 0.01 (ez a gép pontossági tűrése). Becsülje meg annak valószínűségét, hogy egy persely gyártása során az átmérőjének eltérése a névlegestől kisebb lesz, mint 0,5 mm .
Döntés. Legyen r.v. x- a gyártott persely átmérője. Feltétel szerint a matematikai elvárása megegyezik a névleges átmérővel (ha nincs szisztematikus hiba a gép beállításában): a=M(X)=5 , és a szórás D(X)≤0,01. A Csebisev-egyenlőtlenség alkalmazása a ε = 0,5, kapunk:
Így egy ilyen eltérés valószínűsége meglehetősen nagy, ezért arra a következtetésre juthatunk, hogy egy alkatrész egyszeri gyártása esetén az átmérő eltérése a névlegestől szinte biztosan nem haladja meg 0,5 mm .
Alapvetően a szórás σ jellemzi az átlagos egy valószínűségi változó eltérése a középpontjától (vagyis a matematikai elvárásától). Azért, mert az átlagos eltérés, akkor a tesztelés során nagy eltérések (kiemelés az o-ra) lehetségesek. Gyakorlatilag mekkora eltérések lehetségesek? A normális eloszlású valószínűségi változók tanulmányozása során levezettük a „három szigma” szabályt: egy normális eloszlású valószínűségi változót. x egyetlen tesztben gyakorlatilag nem tér el tovább az átlagától, mint 3σ, ahol σ= σ(X) az r.v szórása. x. Ilyen szabályra következtettünk abból, hogy megkaptuk az egyenlőtlenséget
 .
.
Most becsüljük meg ennek valószínűségét tetszőleges valószínűségi változó x olyan értéket fogadjon el, amely az átlagtól legfeljebb a szórás háromszorosával tér el. A Csebisev-egyenlőtlenség alkalmazása a ε = 3σés tekintettel arra D(X)=σ 2 , kapunk:
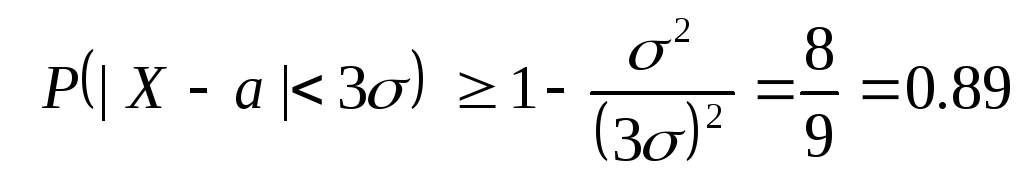 .
.
És így, általában számmal megbecsülhetjük annak valószínűségét, hogy egy valószínűségi változó legfeljebb három szórással tér el az átlagától. 0.89 , míg a normál eloszlásra valószínûséggel garantálható 0.997 .
A Csebisev-egyenlőtlenség független, azonos eloszlású valószínűségi változók rendszerére általánosítható.
Általánosított Csebisev egyenlőtlensége. Ha független valószínűségi változók x 1 , X 2 , … , X n M(x én )= aés diszperziók D(x én )= D, azután
Nál nél n=1 ez az egyenlőtlenség átmegy a fent megfogalmazott Csebisev-egyenlőtlenségbe.
A megfelelő problémák megoldásában önálló jelentőségű Csebisev-egyenlőtlenség az ún. Csebisev-tétel bizonyítására szolgál. Először leírjuk ennek a tételnek a lényegét, majd megadjuk a formális megfogalmazását.
Legyen x 1
, X 2
, … , X n– nagyszámú független valószínűségi változó matematikai elvárásokkal M(X 1
)=a 1
, … , M(X n )=a n. Bár a kísérlet eredményeként mindegyik felvehet az átlagától távol eső értéket (azaz a matematikai elvárást), azonban egy valószínűségi változó  , amelyek számtani átlagukkal megegyeznek, nagy valószínűséggel egy rögzített számhoz közeli értéket vesznek fel
, amelyek számtani átlagukkal megegyeznek, nagy valószínűséggel egy rögzített számhoz közeli értéket vesznek fel  (ez az összes matematikai elvárás átlaga). Ez a következőket jelenti. Legyen a teszt eredményeként független valószínűségi változók x 1
, X 2
, … , X n(sok van belőlük!) ennek megfelelően vették fel az értékeket x 1
, X 2
, … , X n illetőleg. Majd ha ezek az értékek maguk is távol esnek a megfelelő valószínűségi változók átlagértékeitől, akkor az átlagértékük
(ez az összes matematikai elvárás átlaga). Ez a következőket jelenti. Legyen a teszt eredményeként független valószínűségi változók x 1
, X 2
, … , X n(sok van belőlük!) ennek megfelelően vették fel az értékeket x 1
, X 2
, … , X n illetőleg. Majd ha ezek az értékek maguk is távol esnek a megfelelő valószínűségi változók átlagértékeitől, akkor az átlagértékük  valószínűleg közel lesz
valószínűleg közel lesz  . Így nagyszámú valószínűségi változó számtani átlaga már elveszti véletlenszerű jellegét, és nagy pontossággal előre jelezhető. Ez azzal magyarázható, hogy az értékek véletlenszerű eltérései x én tól től a én különböző előjelűek lehetnek, ezért összességében ezek az eltérések nagy valószínűséggel kompenzálódnak.
. Így nagyszámú valószínűségi változó számtani átlaga már elveszti véletlenszerű jellegét, és nagy pontossággal előre jelezhető. Ez azzal magyarázható, hogy az értékek véletlenszerű eltérései x én tól től a én különböző előjelűek lehetnek, ezért összességében ezek az eltérések nagy valószínűséggel kompenzálódnak.
Terema Csebiseva (nagy számok törvénye Csebisev formájában). Legyen x 1 , X 2 , … , X n … páronként független valószínűségi változók sorozata, amelyek varianciái ugyanarra a számra korlátozódnak. Ezután bármilyen kicsi ε számot veszünk, az egyenlőtlenség valószínűsége
önkényesen közel lesz az egységhez, ha a szám n valószínűségi változók ahhoz, hogy elég nagyok legyenek. Formálisan ez azt jelenti, hogy a tétel feltételei között
Az ilyen típusú konvergenciát valószínűségi konvergenciának nevezik, és a következőkkel jelöljük:
Így a Csebisev-tétel azt mondja, hogy ha kellően sok független valószínűségi változó van, akkor azok számtani átlaga egyetlen tesztben szinte biztosan a matematikai várakozásaik átlagához közeli értéket vesz fel.
Leggyakrabban a Csebisev-tételt olyan helyzetben alkalmazzák, amikor a valószínűségi változók x 1 , X 2 , … , X n … azonos eloszlásúak (azaz ugyanaz az eloszlási törvény vagy azonos valószínűségi sűrűség). Valójában ez ugyanannak a valószínűségi változónak csak nagy számú példánya.
Következmény(az általánosított Csebisev-egyenlőtlenségből). Ha független valószínűségi változók x 1 , X 2 , … , X n … azonos eloszlásúak a matematikai elvárásokkal M(x én )= aés diszperziók D(x én )= D, azután
 , azaz
, azaz  .
.
A bizonyítás az általánosított Csebisev-egyenlőtlenségből következik az as határhoz való átlépéssel n→∞ .
Még egyszer megjegyezzük, hogy a fent leírt egyenlőségek nem garantálják a mennyiség értékét  hajlamos a nál nél n→∞. Ez az érték továbbra is egy véletlen változó, és az egyedi értékei meglehetősen távol állnak tőle a. De ennek a valószínűsége (messze nem a) értékeket növekvő mértékben n 0-ra hajlik.
hajlamos a nál nél n→∞. Ez az érték továbbra is egy véletlen változó, és az egyedi értékei meglehetősen távol állnak tőle a. De ennek a valószínűsége (messze nem a) értékeket növekvő mértékben n 0-ra hajlik.
Megjegyzés. A következtetés következtetése nyilvánvalóan érvényes az általánosabb esetben is, amikor a független valószínűségi változók x 1 , X 2 , … , X n … eltérő eloszlásúak, de ugyanazok a matematikai elvárások (egyenlő a) és az összesített eltérések korlátozottak. Ez lehetővé teszi egy bizonyos mennyiség mérési pontosságának előrejelzését, még akkor is, ha ezeket a méréseket különböző műszerekkel végzik.
Tekintsük részletesebben ennek a következménynek a mennyiségek mérésére való alkalmazását. Használjunk valamilyen eszközt n azonos mennyiség mérése, amelynek valódi értéke az aés nem tudjuk. Az ilyen mérések eredményei x 1
, X 2
, … , X n jelentősen eltérhetnek egymástól (és a valódi értéktől a) különböző véletlenszerű tényezők (nyomásesések, hőmérsékletek, véletlenszerű rezgések stb.) miatt. Tekintsük az r.v. x- műszer leolvasása egy mennyiség egyszeri mérésére, valamint egy sor r.v. x 1
, X 2
, … , X n- műszer leolvasása az első, második, ..., utolsó méréskor. Így az egyes mennyiségek x 1
, X 2
, … , X n
csak egy példánya van az r.v. x, és ezért mindegyiknek ugyanaz az eloszlása, mint az r.v. x. Mivel a mérési eredmények egymástól függetlenek, az r.v. x 1
, X 2
, … , X n függetlennek tekinthető. Ha a készülék nem ad szisztematikus hibát (pl. nincs „leütve” a nulla a skálán, nincs megfeszítve a rugó stb.), akkor feltételezhetjük, hogy a matematikai elvárás M(X) = a, és ezért M(X 1
) = ... = M(X n ) = a. Így a fenti következmény feltételei teljesülnek, tehát a mennyiség közelítő értékeként a vehetjük egy valószínűségi változó "megvalósítását".  kísérletünkben (amely egy sorozatból áll n mérések), azaz.
kísérletünkben (amely egy sorozatból áll n mérések), azaz.
 .
.
Nagyszámú mérés mellett az ezzel a képlettel végzett számítás jó pontossága gyakorlatilag megbízható. Ez indokolja azt a gyakorlati elvet, hogy nagy számú mérés mellett ezek számtani átlaga gyakorlatilag nem tér el sokban a mért mennyiség valódi értékétől.
A matematikai statisztikában széles körben használt „mintavételezési” módszer a nagy számok törvényén alapul, amely lehetővé teszi objektív jellemzőinek elfogadható pontosságú meghatározását egy valószínűségi változó viszonylag kis értékéből. De erről a következő részben lesz szó.
Példa. Azon a mérőeszközön, amely nem okoz szisztematikus torzítást, egy bizonyos mennyiséget mérnek a egyszer (kapott értéket x 1
), majd további 99 alkalommal (megszerzett értékek x 2
, … , X 100
). A mérés valódi értékéhez a először vegye le az első mérés eredményét  , majd az összes mérés számtani középértéke
, majd az összes mérés számtani középértéke  . A készülék mérési pontossága olyan, hogy a mérés szórása σ ne legyen nagyobb 1-nél (mivel a szórás D=σ
2
szintén nem haladja meg az 1-et). Mindegyik mérési módszernél becsülje meg annak valószínűségét, hogy a mérési hiba nem haladja meg a 2-t.
. A készülék mérési pontossága olyan, hogy a mérés szórása σ ne legyen nagyobb 1-nél (mivel a szórás D=σ
2
szintén nem haladja meg az 1-et). Mindegyik mérési módszernél becsülje meg annak valószínűségét, hogy a mérési hiba nem haladja meg a 2-t.
Döntés. Legyen r.v. x- műszer leolvasása egyetlen méréshez. Aztán feltételek szerint M(X)=a. A feltett kérdések megválaszolásához az általánosított Csebisev-egyenlőtlenséget alkalmazzuk

ε számára =2
először azért n=1
majd azért n=100
. Az első esetben azt kapjuk  , és a másodikban. Így a második eset gyakorlatilag garantálja az adott mérési pontosságot, míg az első ilyen értelemben komoly kételyeket hagy maga után.
, és a másodikban. Így a második eset gyakorlatilag garantálja az adott mérési pontosságot, míg az első ilyen értelemben komoly kételyeket hagy maga után.
Alkalmazzuk a fenti állításokat a Bernoulli-sémában felmerülő valószínűségi változókra. Emlékezzünk vissza ennek a rendszernek a lényegére. Hagyd előállítani n független tesztek, amelyek mindegyikében valamilyen esemény DE azonos valószínűséggel jelenhetnek meg R, a q=1–r(értelemszerűen ez az ellenkező esemény valószínűsége - nem egy esemény bekövetkezése DE) . Töltsünk el egy kis számot n ilyen tesztek. Tekintsük a véletlen változókat: x 1 – az esemény előfordulásának száma DE ban ben 1 teszt,..., x n– az esemény előfordulásának száma DE ban ben n teszt. Minden bemutatott r.v. értékeket vehet fel 0 vagy 1 (esemény DE megjelenhet a tesztben vagy sem), és az érték 1 feltételesen elfogadott minden kísérletben valószínűséggel p(egy esemény bekövetkezésének valószínűsége DE minden tesztben), és az értéket 0 valószínűséggel q= 1 – p. Ezért ezeknek a mennyiségeknek ugyanazok az eloszlási törvényei:
|
x 1 | ||
|
x n | ||
Ezért ezeknek a mennyiségeknek és diszperzióik átlagértékei is megegyeznek: M(X 1 )=0 ∙ q+1 ∙ p= p, …, M(X n )= p ; D(x 1 )=(0 2 ∙ q+1 2 ∙ p)− p 2 = p∙(1− p)= p ∙ q, … , D(x n )= p ∙ q . Ha ezeket az értékeket behelyettesítjük az általánosított Csebisev-egyenlőtlenségbe, megkapjuk
 .
.
Nyilvánvaló, hogy az r.v. x=x 1 +…+X n az esemény előfordulásának száma DE mindenben n próbák (ahogy mondják - "a sikerek száma"). n tesztek). Engedd be a n teszt esemény DE megjelent k tőlük. Ekkor az előző egyenlőtlenség így írható fel
 .
.
De a nagyságrend  , egyenlő az esemény előfordulásai számának arányával DE ban ben n független kísérletek, a korábban relatív eseményaránynak nevezett kísérletek teljes számához DE ban ben n tesztek. Ezért egyenlőtlenség van
, egyenlő az esemény előfordulásai számának arányával DE ban ben n független kísérletek, a korábban relatív eseményaránynak nevezett kísérletek teljes számához DE ban ben n tesztek. Ezért egyenlőtlenség van
 .
.
Áthaladva most a határig: n→∞, azt kapjuk  , azaz
, azaz  (valószínűség szerint). Ez a tartalma a nagy számok törvényének Bernoulli alakjában. Ebből az következik, hogy kellően nagy számú próbához n a relatív gyakoriság tetszőlegesen kis eltérései
(valószínűség szerint). Ez a tartalma a nagy számok törvényének Bernoulli alakjában. Ebből az következik, hogy kellően nagy számú próbához n a relatív gyakoriság tetszőlegesen kis eltérései  az eseményeket annak valószínűségétől R szinte biztos események, és a nagy eltérések szinte lehetetlenek. Az ebből eredő következtetés a relatív frekvenciák ilyen stabilitásáról (amelyre korábban úgy hivatkoztunk). kísérleti tény) egy esemény valószínűségének korábban bevezetett statisztikai meghatározását olyan számként indokolja, amely körül egy esemény relatív gyakorisága ingadozik.
az eseményeket annak valószínűségétől R szinte biztos események, és a nagy eltérések szinte lehetetlenek. Az ebből eredő következtetés a relatív frekvenciák ilyen stabilitásáról (amelyre korábban úgy hivatkoztunk). kísérleti tény) egy esemény valószínűségének korábban bevezetett statisztikai meghatározását olyan számként indokolja, amely körül egy esemény relatív gyakorisága ingadozik.
Figyelembe véve, hogy a kifejezés p∙
q=
p∙(1−
p)=
p−
p 2
nem haladja meg a váltási intervallumot  (ezt könnyű ellenőrizni, ha ezen a szegmensen megtaláljuk ennek a függvénynek a minimumát), a fenti egyenlőtlenségből
(ezt könnyű ellenőrizni, ha ezen a szegmensen megtaláljuk ennek a függvénynek a minimumát), a fenti egyenlőtlenségből  könnyű megszerezni
könnyű megszerezni
 ,
,
amelyet a megfelelő problémák megoldására használunk (az egyiket az alábbiakban közöljük).
Példa. Az érmét 1000-szer dobták fel. Becsülje meg annak valószínűségét, hogy a címer megjelenésének relatív gyakoriságának a valószínűségétől való eltérése kisebb lesz, mint 0,1!
Döntés. Az egyenlőtlenség alkalmazása  nál nél p=
q=1/2
,
n=1000
,
ε=0,1, kapunk .
nál nél p=
q=1/2
,
n=1000
,
ε=0,1, kapunk .
Példa. Becsülje meg annak valószínűségét, hogy az előző példa feltételei mellett a szám k az elejtett címerek közül a tartományba kerül 400 előtt 600 .
Döntés. Feltétel 400<
k<600
azt jelenti, hogy 400/1000<
k/
n<600/1000
, azaz 0.4<
W n (A)<0.6
vagy  . Ahogy az előző példából láttuk, egy ilyen esemény valószínűsége legalábbis 0.975
.
. Ahogy az előző példából láttuk, egy ilyen esemény valószínűsége legalábbis 0.975
.
Példa. Valamely esemény valószínűségének kiszámítása DE 1000 kísérletet végeztek, amelyben az esemény DE 300 alkalommal jelent meg. Becsülje meg annak valószínűségét, hogy a relatív gyakoriság (300/1000=0,3) eltér a valódi valószínűségtől R legfeljebb 0,1.
Döntés. A fenti egyenlőtlenség alkalmazása  ha n=1000, ε=0,1 , azt kapjuk.
ha n=1000, ε=0,1 , azt kapjuk.