Praksa proučavanja slučajnih pojava pokazuje da iako se rezultati pojedinačnih posmatranja, čak i onih sprovedenih pod istim uslovima, mogu znatno razlikovati, u isto vreme, prosečni rezultati za dovoljno veliki broj posmatranja su stabilni i slabo zavise od rezultati pojedinačnih zapažanja.
Teorijsko opravdanje za ovo izvanredno svojstvo slučajnih pojava je zakon velikih brojeva. Naziv "zakon velikih brojeva" kombinuje grupu teorema koje utvrđuju stabilnost prosječnih rezultata velikog broja slučajnih pojava i objašnjavaju razlog te stabilnosti.
Najjednostavniji oblik zakona velikih brojeva i istorijski prva teorema ovog odjeljka je Bernulijeva teorema navodeći da ako je vjerovatnoća događaja ista u svim pokušajima, onda sa povećanjem broja pokušaja, učestalost događaja teži vjerovatnoći događaja i prestaje biti slučajna.
Poissonova teorema kaže da učestalost događaja u nizu nezavisnih pokušaja teži aritmetičkoj sredini njegovih vjerovatnoća i prestaje biti slučajna.
Granične teoreme teorije vjerovatnoće, teoreme Moivre-Laplace objasni prirodu stabilnosti učestalosti pojavljivanja događaja. Ova priroda se sastoji u činjenici da je granična distribucija broja pojavljivanja događaja uz neograničeno povećanje broja pokušaja (ako je vjerovatnoća događaja u svim pokušajima ista) normalna distribucija.
Centralna granična teorema objašnjava široku upotrebu normalan zakon distribucija. Teorema kaže da kad god se slučajna varijabla formira kao rezultat sabiranja velikog broja nezavisnih slučajnih varijabli sa konačnim varijacijama, zakon distribucije ove slučajne varijable ispada praktički normalno po zakonu.
Teorema ispod, pod naslovom " Zakon velikih brojeva“ tvrdi da pod određenim, prilično opštim, uslovima, sa povećanjem broja slučajnih varijabli, njihova aritmetička sredina teži aritmetičkoj sredini matematičkih očekivanja i prestaje da bude slučajna.
Ljapunovljeva teorema objašnjava rasprostranjenost normalan zakon distribucije i objašnjava mehanizam njenog nastanka. Teorema nam omogućava da tvrdimo da kad god se slučajna varijabla formira kao rezultat sabiranja velikog broja nezavisnih slučajnih varijabli, čije su varijanse male u poređenju sa varijansom zbira, zakon distribucije ove slučajne varijable ispada kao biti praktično normalno po zakonu. A budući da su slučajne varijable uvijek generirane beskonačnim brojem uzroka, a najčešće nijedan od njih nema varijansu uporedivu s varijansom same slučajne varijable, većina slučajnih varijabli koje se susreću u praksi podliježu normalnom zakonu distribucije.
Na osnovu kvalitativnih i kvantitativnih iskaza zakona velikih brojeva Čebiševljeva nejednakost. Definira gornju granicu vjerovatnoće da je odstupanje vrijednosti slučajne varijable od njenog matematičkog očekivanja veće od nekog datog broja. Zanimljivo je da nejednakost Čebiševa daje procjenu vjerovatnoće događaja za slučajnu varijablu čija je distribucija nepoznata, poznati su samo njeno matematičko očekivanje i varijansa.
Čebiševljeva nejednakost. Ako slučajna varijabla x ima varijansu, tada je za bilo koje e > 0 nejednakost ![]() , gdje M x i D x - matematičko očekivanje i varijansa slučajne varijable x .
, gdje M x i D x - matematičko očekivanje i varijansa slučajne varijable x .
Bernulijeva teorema. Neka je m n broj uspjeha u n Bernoullijevih pokušaja, a p vjerovatnoća uspjeha u jednom pokušaju. Tada za bilo koje e > 0 imamo ![]() .
.
Centralna granična teorema. Ako su slučajne varijable x 1 , x 2 , …, x n , … nezavisne po paru, jednako raspoređene i imaju konačnu varijansu, tada na n ® ravnomjerno po x (- ,)
ZAKON O VELIKIM BROJEVIMA
opšti princip, na osnovu kojeg kombinacija slučajnih faktora vodi, pod određenim vrlo opštim uslovima, do rezultata gotovo nezavisnog od slučajnosti. Konvergencija učestalosti pojavljivanja slučajnog događaja sa njegovom vjerovatnoćom s povećanjem broja pokušaja (koje se prvo primjećuje kod kockanja) može poslužiti kao prvi primjer djelovanja ovog principa.
Na prijelazu iz 17. u 18. vijek. J. Bernoulli je dokazao teoremu koja kaže da je u nizu nezavisnih pokušaja, u svakom od kojih pojava određenog događaja A ima istu vrijednost, tačan odnos:
za bilo koji - broj pojavljivanja događaja u prvim ispitivanjima, - učestalost pojavljivanja. Ovo Bernulijeva teorema je proširio S. Poisson na slučaj niza nezavisnih ispitivanja, gdje vjerovatnoća pojave događaja A može zavisiti od broja pokušaja. Neka je ova vjerovatnoća za k-ti ogled jednaka i neka
![]()
Onda Poissonova teorema To navodi
za bilo koji Prvu strogost ove teoreme dao je PL Čebišev (1846), čija se metoda potpuno razlikuje od Poissonove metode i zasniva se na određenim ekstremnim razmatranjima; S. Poisson je izveo (2) iz aproksimativne formule za navedenu vjerovatnoću, zasnovanu na korištenju Gaussovog zakona i u to vrijeme još uvijek nije bila striktno potkrijepljena. S. Poisson se također prvi put susreo s terminom "zakon velikih brojeva", koji je nazvao svojom generalizacijom Bernoullijeve teoreme.
Prirodna daljnja generalizacija Bernoullijevih i Poissonovih teorema javlja se ako primijetimo da se slučajne varijable mogu predstaviti kao zbir
nezavisne slučajne varijable, gdje ako se A pojavljuje u Ath pokusu, i
- inače. Istovremeno, matematički očekivanje (koje se poklapa sa aritmetičkom sredinom matematičkih očekivanja) je jednako p za slučaj Bernoulli i za slučaj Poisson. Drugim riječima, u oba slučaja se uzima u obzir odstupanje aritmetičke sredine X k iz aritmetičke sredine njihove matematičke. očekivanja.
U radu P. L. Čebiševa "Prosječne vrijednosti" (1867) ustanovljeno je da je za nezavisne slučajne varijable relacija
(za bilo koje ) je tačno pod vrlo opštim pretpostavkama. P. L. Čebišev je pretpostavio da matematički. sva očekivanja su ograničena istom konstantom, iako je iz njegovog dokaza jasno da je dovoljno zahtijevati da varijanse budu ograničene
ili čak zahteva
Tako je P. L. Čebišev pokazao mogućnost široke generalizacije Bernulijeve teoreme. A. A. Markov je uočio mogućnost daljnjih generalizacija i predložio korištenje imena B. h. na čitav skup generalizacija Bernoullijeve teoreme [i, posebno, na (3)]. Čebiševljev metod se zasniva na tačnom utvrđivanju opštih svojstava matematike. očekivanja i o upotrebi tzv. Čebiševljeve nejednakosti[za vjerovatnoću (3) daje procjenu oblika
![]()
ova granica se može zamijeniti preciznijom, naravno, sa značajnijim ograničenjima, vidi sl. Bernsteinova nejednakost].
Naknadni dokazi o različitim oblicima B. h. donekle su razvoj metode Čebiševa. Primjenjujući odgovarajuću "redukciju" slučajnih varijabli (zamjenjujući ih pomoćnim varijablama, naime: , ako gdje su neke konstante), A. A. Markov je proširio B. ch. za slučajeve u kojima varijanse termina ne postoje. Na primjer, pokazao je da (3) vrijedi if za neke konstante ![]() i svi i
i svi i
Dio 1 - POGLAVLJE 9. ZAKON VELIKIH BROJEVA. GRANIČNE TEOREME
Sa statističkom definicijomvjerovatnoća, tretira se kao neka
broj prema kojem je srodnik
učestalost slučajnog događaja. At
aksiomatska definicija vjerovatnoće -
to je, u stvari, aditivna mjera skupa
ishodi koji favorizuju šansu
događaj. U prvom slučaju imamo posla
empirijska granica, u drugom - sa
teorijski koncept mjere. Potpuno ne
Očigledno se odnose na isto
koncept. Odnos različitih definicija
vjerovatnoće su utvrđene Bernulijevom teoremom,
što je poseban slučaj zakona velikih
brojevi. Sa povećanjem broja testova
binomski zakon teži tome
normalna distribucija. To je teorema
De Moivre-Laplace, što je
poseban slučaj centralne granice
teoreme. Potonji kaže da je funkcija
raspodjela zbira nezavisnih
slučajne varijable sa povećanjem broja
uslovi teže normalnim
zakon.
Zakon velikih brojeva i centralni
granična teorema leži u osnovi
matematičke statistike.
9.1. Čebiševljeva nejednakost
Neka slučajna varijabla ξ imakonačno matematičko očekivanje
M[ξ] i varijansa D[ξ]. Onda za
bilo koji pozitivan broj ε
tačna je nejednakost:
Bilješke
Za suprotan događaj:Čebiševljeva nejednakost važi za
bilo koji zakon o distribuciji.
Stavljanje
činjenica:
, dobijamo netrivijalno
9.2. Zakon velikih brojeva u Čebiševljevom obliku
Teorema Neka slučajne varijablesu po paru nezavisne i konačne
varijanse ograničene na isto
konstantan
Onda za
bilo koji
imamo
Dakle, zakon velikih brojeva govori o tome
konvergencija u vjerovatnoći aritmetičke sredine slučajnih varijabli (tj. slučajne varijable)
na njihovu aritmetičku sredinu mat. očekivanja (tj.
na neslučajnu vrijednost).
9.2. Zakon velikih brojeva u Čebiševljevom obliku: Komplement
Teorema (Markov): zakon velikihbrojeva je zadovoljena ako je varijansa
zbir slučajnih varijabli ne raste
prebrzo kako n raste:
10.9.3. Bernulijeva teorema
Teorema: Razmotrimo Bernoullijevu šemu.Neka je μn broj pojavljivanja događaja A in
n nezavisnih ispitivanja, p je vjerovatnoća pojave događaja A u jednom
test. Onda za bilo koje
One. vjerovatnoća da će odstupanje
relativna učestalost slučajnog događaja iz
njegova vjerovatnoća p će biti proizvoljno po modulu
mali, teži jedinstvu kako se broj povećava.
testovi n.
11.
Dokaz: Slučajna varijabla μndistribuiran prema binomskom zakonu, dakle
imamo
12.9.4. Karakteristične funkcije
Karakteristična funkcija slučajnogkoličina se naziva funkcija
gdje je exp(x) = ex.
Na ovaj način,
predstavlja
očekivanja nekih
kompleksna slučajna varijabla
povezan sa veličinom. Konkretno, ako
je diskretna slučajna varijabla,
dat redom distribucije (xi, pi), gdje je i
= 1, 2,..., n, onda
13.
Za kontinuiranu slučajnu varijablusa gustinom distribucije
vjerovatnoće
14.
15.9.5. Centralna granična teorema (Ljapunovljev teorem)
16.
Ponovila prošlost17. OSNOVE TEORIJE VEROVATNOĆA I MATEMATIČKE STATISTIKE
DIO II. MATEMATIČKISTATISTIKA
18. Epigraf
„Postoje tri vrste laži: laži,očigledne laži i statistike"
Benjamin Disraeli
19. Uvod
Dva glavna zadatka matematikestatistika:
prikupljanje i grupisanje statističkih
podaci;
razvoj metoda analize
primljeni podaci u zavisnosti od
ciljevi istraživanja.
20. Metode statističke analize podataka:
procjena nepoznate vjerovatnoće događaja;procjena nepoznate funkcije
distribucija;
procjena parametara poznatog
distribucija;
provjera statističkih hipoteza o vrsti
nepoznata distribucija ili
vrijednosti parametara poznatih
distribucija.
21. POGLAVLJE 1. OSNOVNI POJMOVI MATEMATIČKE STATISTIKE
22.1.1. Opća populacija i uzorak
Opća populacija - svimnogo istraženih objekata,
Uzorak - skup objekata, nasumično
izabrani iz opšte populacije
za istraživanje.
Obim opšte populacije i
veličina uzorka - broj objekata u opštoj populaciji i uzorak - hoćemo
označeni kao N i n, respektivno.
23.
Uzorkovanje se ponavlja kadasvaki odabrani objekat
odabirom sljedećeg vraća se na
opšta populacija, i
neponavlja se ako je odabrano
objekta u opštoj populaciji
vraća.
24. Reprezentativni uzorak:
ispravno predstavlja karakteristikeopšta populacija, tj. je
predstavnik (zastupnik).
Prema zakonu velikih brojeva, može se tvrditi da
da je ovaj uslov ispunjen ako:
1) veličina uzorka n je dovoljno velika;
2) svaki predmet uzorka se bira nasumično;
3) za svaki predmet, vjerovatnoća udara
u uzorku je isto.
25.
Opća populacija i uzorakmože biti jednodimenzionalan
(jedan faktor)
i multidimenzionalni (multifaktorski)
26.1.2. Zakon o distribuciji uzorka (statistički niz)
Neka u uzorku veličine nslučajna varijabla koja nas zanima ξ
(bilo koji parametar objekata
stanovništvo) zauzima n1
puta vrijednost x1, n2 puta vrijednost x2,... i
nk puta je vrijednost xk. Zatim posmatrači
vrijednosti x1, x2,..., xk slučajne varijable
ξ se nazivaju varijante, a n1, n2,..., nk
– njihove frekvencije.
27.
Razlika xmax – xmin je rasponuzoraka, odnos ωi = ni /n –
opcije relativne frekvencije xi.
Očigledno je da
28.
Ako opcije zapišemo rastućim redoslijedom, dobićemo varijacioni niz. Sto sastavljen odnaručene varijante i njihove frekvencije
(i/ili relativne frekvencije)
naziva se statistička serija ili
zakon selektivne distribucije.
-- Analog zakona raspodjele diskretnih
slučajna varijabla u teoriji vjerovatnoće
29.
Ako se serija varijacija sastoji od vrlopuno brojeva ili
neki kontinuirani
znak, upotreba grupirana
uzorak. Da biste ga dobili, interval
koji sadrži sve vidljive
vrijednosti karakteristika su podijeljene na
nekoliko obično jednakih dijelova
(podintervali) dužine h. At
sastavljanje statističke serije u
kao xi, obično se biraju sredine
podintervali, i izjednačiti ni sa brojem
varijanta koja je upala u i-ti podinterval.
30.
40- Frekvencije -
35
30
n2
n3
ns
n1
25
20
15
10
5
0
a
a+h/2 a+3h/2
- Opcije -
b-h/2
b
31.1.3. Frekvencijski poligon, funkcija distribucije uzorka
Odgodimo vrijednosti slučajne varijable xi zaapscisa, a ni vrijednosti duž ordinatne ose.
Izlomljena linija čiji se segmenti spajaju
tačke sa koordinatama (x1, n1), (x2, n2),..., (xk,
nk) naziva se poligon
frekvencije. Ako umjesto toga
apsolutne vrijednosti ni
staviti na y-osu
relativne frekvencije ωi,
tada dobijamo poligon relativnih frekvencija
32.
Po analogiji sa funkcijom distribucijediskretna slučajna varijabla po
zakon uzorkovanja distribucije može biti
napraviti uzorak (empirijski)
funkcija distribucije
gdje se sumiranje vrši preko svih
frekvencije, koje odgovaraju vrijednostima
varijanta, manji x. primeti, to
empirijska funkcija distribucije
zavisi od veličine uzorka n.
33.
Za razliku od funkcijepronađeno
za slučajnu varijablu ξ eksperimentalno
kroz obradu statističkih podataka, prave funkcije
distribucija
povezano sa
opšta populacija se zove
teorijski. (obično generalno
agregat je toliko velik da
nemoguće je sve to obraditi;
može samo istražiti
u teoriji).
34.
Obratite pažnju da:35.1.4. Svojstva empirijske funkcije distribucije
stupiopogled
36.
Još jedan grafički prikazuzorak koji nas zanima je
histogram - stepenasta figura,
koji se sastoji od pravougaonika čije su osnove podintervali
širina h, a visine - segmenti dužine
ni/h (histogram frekvencije) ili ωi/h
(histogram relativnih frekvencija).
U prvom slučaju
površina histograma je jednaka zapremini
uzorci n, tokom
druga - jedinica
37. Primjer
38. POGLAVLJE 2. NUMERIČKE KARAKTERISTIKE UZORKA
39.
Zadatak matematičke statistike jenabavite iz dostupnog uzorka
informacije o generalu
agregati. Numeričke karakteristike reprezentativnog uzorka - procjena relevantnih karakteristika
slučajna varijabla koja se proučava,
vezano za opšte
agregat.
40.2.1. Srednja vrijednost uzorka i varijansa uzorka, empirijski momenti
Srednja vrijednost uzorka se zovearitmetička sredina vrijednosti
varijanta u uzorku
Srednja vrijednost uzorka se koristi za
statistička evaluacija matematičkih
očekivanja slučajne varijable koja se proučava.
41.
Varijanca uzorka se zovevrijednost jednaka
Uzorak srednjeg kvadrata
odstupanje -
42.
Lako je pokazati šta se radisljedeća relacija pogodna za
izračun varijanse:
43.
Ostale karakteristikevarijantne serije su:
mod M0 je varijanta koja ima
najveća frekvencija, a medijan me je
varijanta koja dijeli varijantu
red na dva dijela jednaka broju
opcija.
2, 5, 2, 11, 5, 6, 3, 13, 5 (način = 5)
2, 2, 3, 5, 5, 5, 6, 11,13 (medijan = 5)
44.
Po analogiji sa odgovarajućimteorijski izrazi mogu
izgraditi empirijske momente,
koristi se za statistiku
procjene primarnih i centralnih
trenutke slučajnosti
količine.
45.
Po analogiji sa momentimateorije
vjerovatnoće prema početnim empirijskim
moment reda m je količina
centralna empirijska tačka
naručiti m -
46.2.2. Svojstva statističkih procjena parametara distribucije: nepristrasnost, efikasnost, konzistentnost
2.2. Svojstva statističkih procjenaparametri distribucije: nepristrasnost, efikasnost, konzistentnost
Nakon dobijanja statističkih procjena
parametara slučajne distribucije
vrijednosti ξ: srednja vrijednost uzorka, varijansa uzorka, itd., morate se uvjeriti u to
da su dobra aproksimacija
za relevantne parametre
teorijska raspodjela ξ.
Nađimo uslove koji moraju za to
biti izvedena.
47.
48.
Statistički rezultat A* se zovenepristrasan ako je matematički
očekivanje je jednako procijenjenom parametru
opća populacija A za bilo koju
veličina uzorka, tj.
Ako ovaj uslov nije ispunjen, procjena
zove ofset.
Nepristrasna procjena nije dovoljna
uslov za dobru aproksimaciju statistike
bodova A* do prave (teorijske) vrijednosti
procijenjeni parametar A.
49.
Rasipanje individualnih vrijednostiu odnosu na prosječnu vrijednost M
zavisi od varijanse D.
Ako je disperzija velika, onda vrijednost
pronađeno iz podataka jednog uzorka,
mogu se značajno razlikovati od
evaluirani parametar.
Stoga, za pouzdane
varijansa procjene D treba
biti mali. Statistička procjena
naziva se efikasnim ako
s obzirom na veličinu uzorka n, ima
najmanju moguću varijaciju.
50.
Za statističke procjenei dalje uslov
održivost. Rezultat se zove
konzistentan ako je kao n → it
ima tendenciju vjerovatnoće da
parametar koji se procjenjuje. primeti, to
nepristrasna procjena će biti
konzistentan ako je n → njegov
varijansa teži 0.
51. 2.3. Uzorak srednjih svojstava
Pretpostavićemo da su opcije x1, x2,..., xnsu vrijednosti odgovarajućih
nezavisne identično distribuirane slučajne varijable
,
imajući matematička očekivanja
i disperzija
. Onda
srednja vrijednost uzorka može
tretira se kao slučajna varijabla
52.
Nepristrasan. Od nekretninamatematičko očekivanje to implicira
one. srednja vrijednost uzorka je
nepristrasna procjena matematičke
očekivanje slučajne varijable.
Takođe možete pokazati efikasnost
procjene pomoću srednje vrijednosti uzorka matematičkog očekivanja (za normalno
distribucija)
53.
Dosljednost. Neka je a procijenjenoparametar, odnosno matematički
očekivanja stanovništva
– varijansa stanovništva
.
Razmotrimo Čebiševljevu nejednakost
Imamo:
onda
. Kao n → desna strana
nejednakost teži nuli za bilo koje ε > 0, tj.
a time i vrijednost X koja predstavlja uzorak
procjena teži procijenjenom parametru a u smislu vjerovatnoće.
54.
Dakle, može se zaključitida je srednja vrijednost uzorka
nepristrasan, efikasan (prema
barem za normalno
distribucija) i dosljedna
procjena očekivanja
slučajna varijabla povezana sa
opšta populacija.
55.
56.
PREDAVANJE 657. 2.4. Uzorak svojstava varijanse
Istražujemo nepristrasnost varijanse uzorka D* asprocjene varijanse slučajne varijable
58.
59.
60. Primjer
Pronađite srednju vrijednost uzorka, uzorakvarijansu i srednji kvadrat
devijacija, mod i korigovani uzorak
varijansa za uzorak koji ima sljedeće
zakon o distribuciji:
Rješenje:
61.
62. POGLAVLJE 3. TAČKA OCJENA PARAMETARA POZNATE DISTRIBUCIJE
63.
Pretpostavljamo da je opšti oblik zakonadistribucija nam je poznata i
ostaje da razjasnimo detalje -
parametri koji ga definišu
stvarni oblik. Postoji
nekoliko metoda za rješavanje ovog problema
zadataka, od kojih smo dva mi
razmotriti: metodu momenata i metodu
maksimalna vjerovatnoća
64.3.1. Metoda momenata
65.
Metoda momenata koju je razvio CarlPearson 1894. na osnovu
koristeći ove približne jednakosti:
momente
izračunati
teoretski prema poznatom zakonu
distribucije sa parametrima θ, i
ogledni momenti
izračunati
prema raspoloživom uzorku. Nepoznato
parametri
definisano u
rezultat rješavanja sistema r jednačina,
povezivanje relevantno
teorijski i empirijski momenti,
na primjer,
.
66.
Može se pokazati da su procjeneparametri θ dobijeni metodom
trenutke, bogate, njihove
matematička očekivanja su različita
od pravih vrijednosti parametara do
vrijednost reda n–1 i prosjek
standardne devijacije su
vrijednosti reda n–0,5
67. Primjer
Poznato je da je karakteristika ξ objekataopšta populacija, koja je nasumična
vrijednost, ima ujednačenu distribuciju ovisno o parametrima a i b:
Potrebno je odrediti metodom momenata
parametri a i b prema poznatom uzorku
prosjek
i varijansu uzorka
68. Podsjetnik
α1 - matematičko očekivanje β2 - varijansa69.
(*)70.
71.3.2. Metoda maksimalne vjerovatnoće
Metoda se temelji na funkciji vjerovatnoćeL(x1, x2,..., xn, θ), što je zakon
vektorske distribucije
, gdje
slučajne varijable
uzeti vrijednosti
opcija uzorkovanja, tj. imaju isto
distribucija. Pošto su slučajne varijable
su nezavisne, funkcija vjerovatnoće ima oblik:
72.
Ideja o metodi najvećeguvjerljivost leži u činjenici da mi
tražimo takve vrijednosti parametara θ, at
u kojoj je vjerovatnoća pojave
izbor varijanti vrijednosti x1, x2,..., xn
je najveći. Drugim riječima,
kao procjena parametara θ
uzima se vektor za koji je funkcija
vjerovatnoća ima lokalni
maksimum za date x1, x2, …, xn:
73.
Procjene metodom maksimumauvjerljivost se dobija iz
neophodno ekstremno stanje
funkcije L(x1,x2,..., xn,θ) u tački
74. Napomene:
1. Prilikom traženja maksimuma funkcije vjerovatnoćeda biste pojednostavili proračune, možete izvršiti
radnje koje ne mijenjaju rezultat: prvo,
koristiti umjesto L(x1, x2,..., xn,θ) logaritamsku funkciju vjerovatnoće l(x1, x2,..., xn,θ) =
log L(x1, x2,..., xn,θ); drugo, odbaciti u izrazu
za funkciju vjerovatnoće nezavisnu od θ
termini (za l) ili pozitivni
faktori (za L).
2. Procjene parametara koje mi razmatramo su
može se nazvati tačkastim procjenama, jer za
nepoznati parametar θ, jedan
jedna tačka
, koji je njegov
približna vrijednost. Međutim, ovaj pristup
može dovesti do grubih grešaka i poenta
procjena se može značajno razlikovati od istinite
vrijednosti procijenjenog parametra (posebno u
mala veličina uzorka).
75. Primjer
Rješenje. U ovom zadatku potrebno je vrednovatidva nepoznata parametra: a i σ2.
Log-likelihood funkcija
ima oblik
76.
Odbacivanje izraza u ovoj formuli, koji nijezavisi od a i σ2, sastavljamo sistem jednadžbi
kredibilitet
Rešavajući, dobijamo:
77. POGLAVLJE 4. INTERVALNA OCJENA PARAMETARA POZNATE DISTRIBUCIJE
78.
(*)
79.
(*)80.4.1. Procjena matematičkog očekivanja normalno raspoređene veličine sa poznatom varijansom
srednja vrijednost uzorka
kao slučajna vrijednost
81.
Imamo:(1)
(2)
82.
(2)(1)
(*)
(*)
83.4.2. Procjena matematičkog očekivanja normalno raspoređene veličine s nepoznatom varijansom
84.
stepena slobode. Gustina
količine su
85.
86. Studentova raspodjela gustine sa n - 1 stepenom slobode
87.
88.
89.
pronađite po formulama
90. 4.3. Procjena standardne devijacije normalno raspoređene veličine
odstupanje σ.
nepoznato matematičko
čekanje.
91. 4.3.1. Poseban slučaj dobro poznatog matematičkog očekivanja
Koristeći količine
,
varijansa uzorka D*:
92.
količine
imati normalan
93.
uslovi
gdje
je gustina raspodjele χ2
94.
95.
96.
97.4.3.2. Poseban slučaj nepoznatog matematičkog očekivanja
(gdje je slučajna varijabla
χ2 sa n–1 stepena slobode.
98.
99.4.4. Procjena matematičkog očekivanja slučajne varijable za proizvoljan uzorak
veliki uzorak (n >> 1).
100.
količine
vlasništvo
disperzija
, i rezultirajući
srednja vrijednost uzorka
kao vrijednost
slučajna varijabla
magnitude
ima asimptotski
.
101.
koristite formulu
102.
103.
Predavanje 7104.
Ponavljanje prošlosti105. POGLAVLJE 4. INTERVALNA OCJENA PARAMETARA POZNATE DISTRIBUCIJE
106.
Problem procjene nekog poznatog parametradistribucije se mogu riješiti pomoću
konstruisanje intervala u kojem, sa datim
verovatna je prava vrednost
parametar. Ova metoda evaluacije
naziva se intervalna procjena.
Obično iz matematike za evaluaciju
parametar θ, konstruišemo nejednakost
(*)
gdje broj δ karakterizira tačnost procjene:
što je manji δ, to je bolja procjena.
107.
(*)108.4.1. Procjena matematičkog očekivanja normalno raspoređene veličine sa poznatom varijansom
Neka se slučajna varijabla ξ koja se proučava raspoređuje prema normalnom zakonu sa poznatimstandardna devijacija σ i
nepoznato matematičko očekivanje a.
Zahtijeva vrijednost srednje vrijednosti uzorka
procijeniti matematičko očekivanje ξ.
Kao i prije, razmotrit ćemo rezultat
srednja vrijednost uzorka
kao slučajna vrijednost
vrijednosti, a vrijednosti su varijanta uzorka x1, x2,…,
xn - respektivno, pošto su vrijednosti iste
distribuirane nezavisne slučajne varijable
, od kojih svaka ima prostirku. očekivanje a i standardna devijacija σ.
109.
Imamo:(1)
(2)
110.
(2)(1)
(*)
(*)
111.4.2. Procjena matematičkog očekivanja normalno raspoređene veličine s nepoznatom varijansom
112.
Poznato je da je slučajna varijabla tn,dato na ovaj način ima
Studentova raspodjela sa k = n - 1
stepena slobode. Gustina
distribuciju vjerovatnoće takvih
količine su
113.
114. Studentova raspodjela gustine sa n - 1 stepenom slobode
115.
116.
117.
Bilješka. Sa velikim brojem stepenisloboda k Studentova distribucija
teži normalnoj distribuciji sa
nulto matematičko očekivanje i
pojedinačna varijansa. Dakle, za k ≥ 30
interval povjerenja može biti u praksi
pronađite po formulama
118. 4.3. Procjena standardne devijacije normalno raspoređene veličine
Neka se slučajna varijabla proučavaξ se distribuira prema normalnom zakonu
sa očekivanjem a i
nepoznati srednji kvadrat
odstupanje σ.
Razmotrimo dva slučaja: sa poznatim i
nepoznato matematičko
čekanje.
119. 4.3.1. Poseban slučaj dobro poznatog matematičkog očekivanja
Neka je poznata vrijednost M[ξ] = a iprocijeniti samo σ ili varijansu D[ξ] = σ2.
Podsjetimo to za poznatu prostirku. čekanje
nepristrasna procjena varijanse je
varijansa uzorka D* = (σ*)2
Koristeći količine
,
definirano gore, uvodimo slučajni
vrijednost Y, koja preuzima vrijednosti
varijansa uzorka D*:
120.
Uzmite u obzir slučajnu varijabluZbroji pod znakom su nasumični
količine
imati normalan
raspodjela sa gustinom fN (x, 0, 1).
Tada Hn ima distribuciju χ2 sa n
stepeni slobode kao zbir kvadrata n
nezavisni standard (a = 0, σ = 1)
normalne slučajne varijable.
121.
Odredimo interval povjerenja izuslovi
gdje
je gustina raspodjele χ2
i γ - pouzdanost (pouzdanje
vjerovatnoća). Vrijednost γ je numerički jednaka
područje zasjenjene figure na sl.
122.
123.
124.
125. 4.3.2. Poseban slučaj nepoznatog matematičkog očekivanja
U praksi najčešća situacijakada su oba parametra normale nepoznata
distribucije: matematičko očekivanje a i
standardna devijacija σ.
U ovom slučaju, izgradnja povjerenja
interval je zasnovan na Fisherovoj teoremi, iz
mačka. slijedi da je slučajna varijabla
(gdje je slučajna varijabla
uzimajući vrijednosti nepristrasnog
varijansa uzorka s2 ima distribuciju
χ2 sa n–1 stepena slobode.
126.
127.4.4. Procjena matematičkog očekivanja slučajne varijable za proizvoljan uzorak
Intervalne procjene matematičkihočekivanja M[ξ] dobijena za normalno
distribuirana slučajna varijabla ξ ,
općenito su neprikladni za
slučajne varijable koje imaju drugačiji oblik
distribucija. Međutim, postoji situacija u kojoj
za bilo koje slučajne varijable
koristite slične intervale
odnosima, to se dešava u
veliki uzorak (n >> 1).
128.
Kao što je gore navedeno, razmotrit ćemo opcijex1, x2,..., xn kao nezavisne vrijednosti,
jednako raspoređena nasumično
količine
vlasništvo
očekivanje M[ξi] = mξ i
disperzija
, i rezultirajući
srednja vrijednost uzorka
kao vrijednost
slučajna varijabla
Prema središnjoj graničnoj teoremi
magnitude
ima asimptotski
zakon normalne distribucije c
očekivanje mξ i varijansu
.
129.
Dakle, ako je poznata vrijednost varijanseslučajna varijabla ξ, onda možemo
koristite približne formule
Ako je vrijednost disperzije veličine ξ
nepoznato, onda za veliko n može
koristite formulu
gdje je s korigirani rms. odstupanje
130.
Ponovila prošlost131. POGLAVLJE 5. PROVJERA STATISTIČKIH HIPOTEZA
132.
Statistička hipoteza je hipoteza oobliku nepoznate distribucije ili o parametrima
poznata distribucija slučajne varijable.
Hipoteza koju treba testirati, obično se označava kao
H0 se naziva nultom ili glavnom hipotezom.
Dodatno korištena hipoteza H1,
u suprotnosti sa hipotezom H0 se naziva
konkurentske ili alternativne.
Statistička provjera napredne nule
hipoteza H0 sastoji se u njenom poređenju sa
uzorak podataka. Sa takvim čekom
Mogu se pojaviti dvije vrste grešaka:
a) greške prve vrste - slučajevi kada je odbijen
tačna hipoteza H0;
b) greške druge vrste - slučajevi kada
prihvata se pogrešna hipoteza H0.
133.
Vjerovatnoća greške prve vrste će bitinazovite nivo značaja i odredite
kao.
Glavna tehnika za provjeru statističkih podataka
hipoteza je to
raspoloživom uzorku, vrijednost se izračunava
statistički kriterijum - neki
slučajna varijabla T sa poznatim
zakon o distribuciji. Raspon vrijednosti T,
pod kojim glavna hipoteza H0 mora
biti odbačen, nazvan kritičnim i
raspon vrijednosti T za koji je ova hipoteza
može se prihvatiti, - područje prihvata
hipoteze.
134.
135.5.1. Testiranje hipoteza o parametrima poznate distribucije
5.1.1. Provjera hipoteza o matematiciočekivanje normalno raspoređene slučajnosti
količine
Neka slučajna varijabla ξ ima
normalna distribucija.
Moramo provjeriti pretpostavku da
da je njegovo matematičko očekivanje
neki broj a0. Razmotrite odvojeno
slučajevima kada je varijansa ξ poznata i kada
ona je nepoznata.
136.
U slučaju poznate disperzije D[ξ] = σ2,kao u § 4.1, definišemo slučajnost
vrijednost koja preuzima vrijednosti
srednja vrijednost uzorka. Hipoteza H0
prvobitno formulisan kao M[ξ] =
a0. Zato što uzorak znači
je nepristrasna procjena M[ξ], dakle
hipoteza H0 se može predstaviti kao
137.
S obzirom na nepristrasnost ispravljenogvarijanse uzorka, nulta hipoteza može biti
napiši ovako:
gdje je slučajna varijabla
uzima vrijednosti korigovanog uzorka
disperzija ξ i slična je slučajnoj
vrijednost Z razmatrana u Odjeljku 4.2.
Kao statistički kriterijum biramo
slučajna varijabla
uzimajući vrijednost omjera većeg
varijansu uzorka na manju.
145.
Slučajna varijabla F imaFisher-Snedecor distribucija sa
broj stepena slobode k1 = n1 – 1 i k2
= n2 – 1, gdje je n1 veličina uzorka, prema
koji je veći
korigovana varijansa
, i n2
volumen drugog uzorka, za koji
pronašao manju varijaciju.
Razmotrite dvije vrste nadmetanja
hipoteze
146.
147.
148. 5.1.3. Poređenje matematičkih očekivanja nezavisnih slučajnih varijabli
Razmotrimo prvo slučaj normaledistribucije slučajnih varijabli sa poznatim
varijanse, a zatim na osnovu toga - opštije
slučaju proizvoljne raspodjele količina na
dovoljno veliki nezavisni uzorci.
Neka su slučajne varijable ξ1 i ξ2 nezavisne i
su normalno raspoređeni i neka su njihove varijanse D[ξ1]
i D[ξ2] su poznati. (Na primjer, mogu se naći
iz nekog drugog iskustva ili proračunato
u teoriji). Ekstrahovani uzorci veličine n1 i n2
respektivno. Neka bude
– selektivno
prosjeci za ove uzorke. Zahtijeva selektivno
prosjek na datom nivou značajnosti α
testirati hipotezu o jednakosti matematičke
očekivanja da će se razmatrane slučajne varijable napraviti iz apriornih razmatranja,
na osnovu eksperimentalnih uslova, i
zatim pretpostavke o parametrima
distribucije se ispituju kao što je prikazano
prethodno. Međutim, vrlo često postoji
potreba za verifikacijom
hipoteza o zakonu distribucije.
Dizajnirani statistički testovi
za takve provjere se obično pozivaju
kriterijumi saglasnosti.
154.
Poznato je nekoliko kriterijuma za sporazum. DostojanstvoPearsonov kriterijum je njegova univerzalnost. Sa njegovim
može se koristiti za testiranje hipoteza o različitim
zakoni o distribuciji.
Pearsonov kriterijum se zasniva na poređenju frekvencija,
pronađeno iz uzorka (empirijske frekvencije), s
frekvencije izračunate pomoću testiranih
zakon raspodjele (teorijske frekvencije).
Obično empirijske i teorijske frekvencije
razlikuju se. Moramo otkriti da li je to slučajnost
frekvencijska razlika ili je značajna i objašnjena
činjenica da su teorijske frekvencije izračunate na osnovu
netačna hipoteza o raspodjeli općeg
agregati.
Pirsonov kriterijum, kao i svaki drugi, odgovara na
Pitanje je da li postoji saglasnost između predložene hipoteze i
empirijski podaci na datom nivou
značaj.
155. 5.2.1. Testiranje hipoteze normalne distribucije
Neka postoji slučajna varijabla ξ i nekauzorak dovoljno velike veličine n sa velikim
broj različitih vrijednosti opcija. Obavezno
na nivou značajnosti α, testirati nultu hipotezu
H0 da je slučajna varijabla ξ distribuirana
u redu.
Radi praktičnosti obrade uzorka, uzimamo dva broja
α i β:
i podijelite interval [α, β] sa s
podintervali. Pretpostavićemo da su vrednosti varijante,
koji spadaju u svaki podinterval su približno jednaki
broj koji specificira sredinu podintervala.
Računajući broj opcija koje spadaju u svaki kvantil reda α (0< α < 1) непрерывной
slučajna varijabla ξ je takav broj xα,
za koje je jednakost
.
Kvantil x½ se naziva medijanom slučajnog
veličine ξ, kvantili x0 i x2 su njegovi kvartili, a
x0.1, x0.2,..., x0.9 - decili.
Za standardnu normalnu distribuciju (a =
0, σ = 1) i, prema tome,
gdje je FN (x, a, σ) normalna funkcija raspodjele
distribuirana slučajna varijabla, i Φ(x)
Laplaceova funkcija.
Kvantil standardne normalne distribucije
xα za dato α se može naći iz relacije
162.6.2. Distribucija učenika
Ako– nezavisni
slučajne varijable koje imaju
normalna distribucija sa nulom
matematičko očekivanje i
jedinična varijansa, dakle
distribucija slučajne varijable
nazvana Studentova t-distribucija
sa n stepeni slobode (W.S. Gosset).
Zakon velikih brojeva u teoriji vjerovatnoće navodi da je empirijska sredina (aritmetička sredina) dovoljno velikog konačnog uzorka iz fiksne distribucije blizu teorijske sredine (očekivanja) ove distribucije. U zavisnosti od vrste konvergencije, razlikuje se slab zakon velikih brojeva, kada postoji konvergencija u verovatnoći, i jak zakon velikih brojeva, kada postoji konvergencija gotovo svuda.
Uvijek postoji konačan broj pokušaja za koje je, sa bilo kojom datom vjerovatnoćom, manji od 1 relativna učestalost pojave nekog događaja će se proizvoljno malo razlikovati od njegove vjerovatnoće.
Opšte značenje zakona velikih brojeva: zajedničko djelovanje velikog broja identičnih i nezavisnih slučajnih faktora dovodi do rezultata koji, u krajnjoj liniji, ne ovisi o slučaju.
Metode za procjenu vjerovatnoće zasnovane na analizi konačnog uzorka zasnivaju se na ovoj osobini. Dobar primjer je predviđanje izbornih rezultata na osnovu ankete uzorka birača.
Encyclopedic YouTube
1 / 5
✪ Zakon velikih brojeva
✪ 07 - Teorija vjerovatnoće. Zakon velikih brojeva
✪ 42 Zakon velikih brojeva
✪ 1 - Čebiševljev zakon velikih brojeva
✪ 11. razred, lekcija 25, Gausova kriva. Zakon velikih brojeva
Titlovi
Pogledajmo zakon velikih brojeva, koji je možda najintuitivniji zakon u matematici i teoriji vjerovatnoće. A pošto se odnosi na mnogo stvari, ponekad se koristi i pogrešno shvata. Dozvolite mi da prvo dam definiciju za tačnost, a onda ćemo razgovarati o intuiciji. Uzmimo slučajnu varijablu, recimo X. Recimo da znamo njeno matematičko očekivanje ili srednju vrijednost populacije. Zakon velikih brojeva jednostavno kaže da ako uzmemo primjer n-tog broja posmatranja slučajne varijable i usredsredimo broj svih tih opservacija... Uzmimo varijablu. Nazovimo ga X sa indeksom n i crticom na vrhu. Ovo je aritmetička sredina n-tog broja posmatranja naše slučajne varijable. Evo mog prvog zapažanja. Uradim eksperiment jednom i napravim ovo zapažanje, zatim uradim to ponovo i napravim ovo zapažanje, uradim to ponovo i dobijem ovo. Izvršim ovaj eksperiment n puta i onda podijelim s brojem svojih zapažanja. Evo srednje vrijednosti mog uzorka. Evo prosjeka svih zapažanja koje sam napravio. Zakon velikih brojeva nam govori da će srednja vrijednost mog uzorka aproksimirati srednju vrijednost slučajne varijable. Ili također mogu napisati da će se moja srednja vrijednost uzorka približiti srednjoj vrijednosti populacije za n-ti broj koji ide u beskonačnost. Neću praviti jasnu razliku između "aproksimacije" i "konvergencije", ali se nadam da intuitivno razumete da ako ovde uzmem prilično veliki uzorak, onda dobijam očekivanu vrednost za populaciju u celini. Mislim da većina vas intuitivno razumije da ako uradim dovoljno testova sa velikim uzorkom primjera, na kraju će mi testovi dati vrijednosti koje očekujem, uzimajući u obzir matematičko očekivanje, vjerovatnoću i sve to. Ali mislim da je često nejasno zašto se to dešava. I prije nego što počnem da objašnjavam zašto je to tako, daću vam konkretan primjer. Zakon velikih brojeva nam govori da... Recimo da imamo slučajnu varijablu X. Ona je jednaka broju glava u 100 bacanja ispravnog novčića. Prije svega, znamo matematičko očekivanje ove slučajne varijable. Ovo je broj bacanja novčića ili pokušaja pomnožen sa izgledima da bilo koji pokušaj uspije. Dakle, jednako je 50. Odnosno, zakon velikih brojeva kaže da ako uzmemo uzorak, ili ako uprosim ove testove, dobijam. .. Prvi put kada radim test, bacim novčić 100 puta, ili uzmem kutiju od sto novčića, protresem je i onda izbrojim koliko glava dobijem i dobijem, recimo, broj 55. Ovo će biti X1. Zatim ponovo protresem kutiju i dobijem broj 65. Zatim ponovo - i dobijem 45. I uradim ovo n puta, i onda to podijelim sa brojem pokušaja. Zakon velikih brojeva nam govori da će ovaj prosjek (prosjek svih mojih zapažanja) težiti 50 dok će n težiti beskonačnosti. Sada bih želeo da pričam malo o tome zašto se to dešava. Mnogi smatraju da ako je moj rezultat nakon 100 pokušaja iznad prosjeka, onda bih, prema zakonima vjerovatnoće, trebao imati više ili manje glave kako bih, da tako kažem, nadoknadio razliku. To nije tačno ono što će se dogoditi. Ovo se često naziva "kockarska zabluda". Dozvolite mi da vam pokažem razliku. Koristit ću sljedeći primjer. Da nacrtam grafik. Hajde da promenimo boju. Ovo je n, moja x-osa je n. Ovo je broj testova koje ću izvršiti. I moja y-osa će biti srednja vrijednost uzorka. Znamo da je srednja vrijednost ove proizvoljne varijable 50. Pusti me da nacrtam ovo. Ovo je 50. Vratimo se na naš primjer. Ako je n... Tokom mog prvog testa, dobio sam 55, što je moj prosjek. Imam samo jednu tačku za unos podataka. Onda, nakon dva pokušaja, dobijem 65. Dakle, moj prosjek bi bio 65+55 podijeljen sa 2. To je 60. I moj prosjek je malo porastao. Onda sam dobio 45, što je opet snizilo moju aritmetičku sredinu. Neću ucrtati na grafikonu 45. Sada moram sve izmjeriti u prosjeku. Čemu je jednako 45+65? Dozvolite mi da izračunam ovu vrijednost da predstavim tačku. To je 165 podeljeno sa 3. To je 53. Ne, 55. Dakle, prosek se ponovo spušta na 55. Možemo nastaviti sa ovim testovima. Nakon što smo uradili tri pokusa i došli do ovog prosjeka, mnogi ljudi misle da će bogovi vjerovatnoće učiniti tako da u budućnosti dobijemo manje glava, da će sljedećih nekoliko pokušaja biti niži kako bi smanjili prosjek. Ali nije uvijek tako. U budućnosti, vjerovatnoća uvijek ostaje ista. Vjerovatnoća da ću se vrtjeti uvijek će biti 50%. Nije da u početku dobijem određeni broj glava, više nego što očekujem, a onda bi odjednom trebalo da ispadnu repovi. Ovo je "igračeva zabluda". Ako dobijete neproporcionalan broj glava, to ne znači da će vam u jednom trenutku početi ispadati nesrazmjeran broj repova. Ovo nije sasvim tačno. Zakon velikih brojeva nam govori da to nije bitno. Recimo, nakon određenog konačnog broja pokušaja, vaš prosek... Verovatnoća za to je prilično mala, ali, ipak... Recimo da vaš prosek dostiže ovu oznaku - 70. Razmišljate: "Vau, otišli smo daleko iznad očekivanja." Ali zakon velikih brojeva kaže da nije važno koliko testova izvodimo. Pred nama je još beskonačan broj iskušenja. Matematičko očekivanje ovog beskonačnog broja pokušaja, posebno u sličnoj situaciji, bit će sljedeće. Kada dođete do konačnog broja koji izražava neku veliku vrijednost, beskonačan broj koji konvergira s njim opet će dovesti do očekivane vrijednosti. Ovo je, naravno, vrlo labavo tumačenje, ali to nam govori zakon velikih brojeva. Važno je. On nam ne kaže da ako dobijemo mnogo glava, onda će se nekako povećati šanse da dobijemo repove da bismo to nadoknadili. Ovaj zakon nam govori da nije važno kakav će biti ishod sa konačnim brojem suđenja sve dok još uvijek imate beskonačan broj suđenja pred vama. A ako ih napravite dovoljno, ponovo ćete se vratiti očekivanjima. Ovo je važna tačka. Razmisli o tome. Ali to se ne koristi svakodnevno u praksi sa lutrijama i kockarnicama, iako se zna da ako uradite dovoljno testova... Možemo i izračunati... kolika je vjerovatnoća da ćemo ozbiljno odstupiti od norme? Ali kockarnice i lutrije rade svaki dan po principu da ako uzmete dovoljno ljudi, naravno, za kratko vrijeme, sa malim uzorkom, onda će nekoliko ljudi osvojiti džekpot. Ali dugoročno, kazino će uvijek imati koristi od parametara igara u koje vas pozivaju da igrate. Ovo je važan princip vjerovatnoće koji je intuitivan. Iako ponekad, kada vam se to formalno objasni slučajnim varijablama, sve to izgleda pomalo zbunjujuće. Sve što ovaj zakon kaže je da što više uzoraka ima, to će se aritmetička sredina tih uzoraka više približavati pravoj sredini. I da budemo precizniji, aritmetička sredina vašeg uzorka će konvergirati s matematičkim očekivanjem slučajne varijable. To je sve. Vidimo se u sljedećem videu!
Slab zakon velikih brojeva
Slab zakon velikih brojeva naziva se i Bernoullijevom teoremom, po Jacobu Bernoulliju, koji ga je dokazao 1713. godine.
Neka postoji beskonačan niz (uzastopno nabrajanje) identično raspoređenih i nekoreliranih slučajnih varijabli. To jest, njihova kovarijansa c o v (X i , X j) = 0 , ∀ i ≠ j (\displaystyle \mathrm (cov) (X_(i),X_(j))=0,\;\forall i\not =j). Neka bude . Označiti uzorkom srednje vrijednosti prvog n (\displaystyle n)članovi:
.
Onda X ¯ n → P μ (\displaystyle (\bar (X))_(n)\to ^(\!\!\!\!\!\!\mathbb (P) )\mu ).
Odnosno za svaku pozitivu ε (\displaystyle \varepsilon )
lim n → ∞ Pr (| X ¯ n − μ |< ε) = 1. {\displaystyle \lim _{n\to \infty }\Pr \!\left(\,|{\bar {X}}_{n}-\mu |<\varepsilon \,\right)=1.}Jaki zakon velikih brojeva
Neka postoji beskonačan niz nezavisnih identično raspoređenih slučajnih varijabli ( X i ) i = 1 ∞ (\displaystyle \(X_(i)\)_(i=1)^(\infty )) definisano na jednom verovatnosnom prostoru (Ω, F, P) (\displaystyle (\Omega,(\mathcal (F)),\mathbb (P))). Neka bude E X i = μ , ∀ i ∈ N (\displaystyle \mathbb (E) X_(i)=\mu ,\;\forall i\in \mathbb (N) ). Označiti sa X¯n (\displaystyle (\bar(X))_(n)) uzorak srednje vrijednosti prvog n (\displaystyle n)članovi:
X ¯ n = 1 n ∑ i = 1 n X i , n ∈ N (\displaystyle (\bar (X))_(n)=(\frac (1)(n))\sum \limits _(i= 1)^(n)X_(i),\;n\in \mathbb (N) ).Onda X ¯ n → μ (\displaystyle (\bar (X))_(n)\to \mu ) skoro uvijek.
Pr (lim n → ∞ X ¯ n = μ) = 1. (\displaystyle \Pr \!\left(\lim _(n\to \infty )(\bar (X))_(n)=\mu \ desno)=1.) .Kao i svaki matematički zakon, zakon velikih brojeva može se primijeniti na stvarni svijet samo pod poznatim pretpostavkama, koje se mogu ispuniti samo sa određenim stepenom tačnosti. Tako, na primjer, uslovi uzastopnih testova često se ne mogu održavati neograničeno i sa apsolutnom tačnošću. Osim toga, zakon velikih brojeva samo govori o tome nevjerovatnost značajno odstupanje srednje vrijednosti od matematičkog očekivanja.
Riječi o velikim brojevima odnose se na broj testova - razmatra se veliki broj vrijednosti slučajne varijable ili kumulativno djelovanje velikog broja slučajnih varijabli. Suština ovog zakona je sljedeća: iako je nemoguće predvidjeti koju će vrijednost pojedinačna slučajna varijabla poprimiti u jednom eksperimentu, međutim, ukupni rezultat djelovanja velikog broja nezavisnih slučajnih varijabli gubi svoj slučajni karakter i može biti predvidjeti gotovo pouzdano (tj. sa velikom vjerovatnoćom). Na primjer, nemoguće je predvidjeti na koju će stranu novčić pasti. Međutim, ako bacite 2 tone novčića, onda se s velikim povjerenjem može tvrditi da je težina novčića koji su pali s grbom gore 1 tona.
Prije svega, takozvana Čebiševljeva nejednakost se odnosi na zakon velikih brojeva, koji u posebnom testu procjenjuje vjerovatnoću prihvatanja vrijednosti pomoću slučajne varijable koja odstupa od prosječne vrijednosti za najviše datu vrijednost.
Čebiševljeva nejednakost. Neka bude X je proizvoljna slučajna varijabla, a=M(X) , ali D(X) je njegova disperzija. Onda
Primjer. Nazivna (tj. potrebna) vrijednost prečnika čahure obrađene na mašini je 5mm, a varijanse više nema 0.01 (ovo je tolerancija tačnosti mašine). Procijenite vjerovatnoću da će u proizvodnji jedne čaure odstupanje njenog prečnika od nominalnog biti manje od 0.5mm .
Rješenje. Neka r.v. X- prečnik proizvedene čahure. Po uslovu, njegovo matematičko očekivanje je jednako nominalnom prečniku (ako nema sistematskog kvara u postavljanju mašine): a=M(X)=5 , i varijansu D(X)≤0,01. Primjenom Čebiševe nejednakosti za ε = 0,5, dobijamo:
Dakle, vjerovatnoća ovakvog odstupanja je prilično velika, te stoga možemo zaključiti da u slučaju pojedinačne proizvodnje dijela, odstupanje prečnika od nominalnog gotovo sigurno neće premašiti 0.5mm .
U osnovi, standardna devijacija σ karakteriše prosječna odstupanje slučajne varijable od njenog centra (tj. od njenog matematičkog očekivanja). Jer prosječna odstupanja, tada su moguća velika odstupanja (naglasak na o) tokom testiranja. Koliko su velika odstupanja praktično moguća? Kada smo proučavali normalno raspoređene slučajne varijable, izveli smo pravilo "tri sigma": normalno raspoređena slučajna varijabla X u jednom testu praktično ne odstupa od svog prosjeka dalje od 3σ, gdje σ= σ(X) je standardna devijacija r.v. X. Takvo pravilo smo izveli iz činjenice da smo dobili nejednakost
 .
.
Procijenimo sada vjerovatnoću za proizvoljno slučajna varijabla X prihvati vrijednost koja se razlikuje od srednje vrijednosti za najviše tri puta standardnu devijaciju. Primjenom Čebiševe nejednakosti za ε = 3σ i s obzirom na to D(X)=σ 2 , dobijamo:
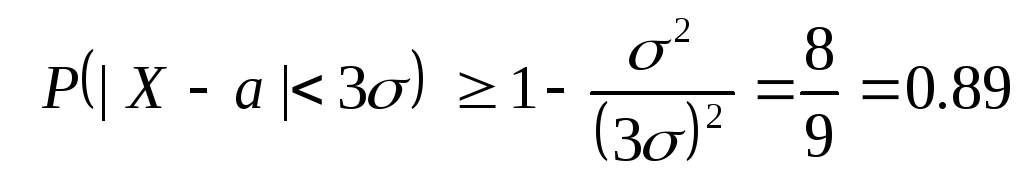 .
.
Na ovaj način, Uglavnom možemo procijeniti vjerovatnoću slučajne varijable koja odstupa od srednje vrijednosti za najviše tri standardne devijacije po broju 0.89 , dok se za normalnu distribuciju može garantovati sa vjerovatnoćom 0.997 .
Čebiševljeva nejednakost se može generalizirati na sistem nezavisnih identično distribuiranih slučajnih varijabli.
Generalizirana Čebiševljeva nejednakost. Ako su nezavisne slučajne varijable X 1 , X 2 , … , X n M(X i )= a i disperzije D(X i )= D, onda
At n=1 ova nejednakost prelazi u nejednakost Čebiševa formulisanu gore.
Čebiševljeva nejednakost, koja ima nezavisan značaj za rješavanje odgovarajućih problema, koristi se za dokazivanje takozvane Čebiševljeve teoreme. Prvo ćemo opisati suštinu ove teoreme, a zatim dati njenu formalnu formulaciju.
Neka bude X 1
, X 2
, … , X n– veliki broj nezavisnih slučajnih varijabli sa matematičkim očekivanjima M(X 1
)=a 1
, … , M(X n )=a n. Iako svaki od njih, kao rezultat eksperimenta, može uzeti vrijednost daleko od svog prosjeka (tj. matematičkog očekivanja), međutim, slučajna varijabla  , jednak njihovoj aritmetičkoj sredini, sa velikom vjerovatnoćom će poprimiti vrijednost blizu fiksnog broja
, jednak njihovoj aritmetičkoj sredini, sa velikom vjerovatnoćom će poprimiti vrijednost blizu fiksnog broja  (ovo je prosjek svih matematičkih očekivanja). To znači sljedeće. Neka, kao rezultat testa, nezavisne slučajne varijable X 1
, X 2
, … , X n(ima ih puno!) uzeli su vrijednosti u skladu s tim X 1
, X 2
, … , X n respektivno. Zatim, ako se te vrijednosti mogu pokazati daleko od prosječnih vrijednosti odgovarajućih slučajnih varijabli, njihova prosječna vrijednost
(ovo je prosjek svih matematičkih očekivanja). To znači sljedeće. Neka, kao rezultat testa, nezavisne slučajne varijable X 1
, X 2
, … , X n(ima ih puno!) uzeli su vrijednosti u skladu s tim X 1
, X 2
, … , X n respektivno. Zatim, ako se te vrijednosti mogu pokazati daleko od prosječnih vrijednosti odgovarajućih slučajnih varijabli, njihova prosječna vrijednost  vjerovatno će biti blizu
vjerovatno će biti blizu  . Dakle, aritmetička sredina velikog broja slučajnih varijabli već gubi svoj slučajni karakter i može se predvidjeti sa velikom preciznošću. Ovo se može objasniti činjenicom da su slučajna odstupanja vrijednosti X i od a i mogu biti različitih predznaka, te se stoga u zbiru ova odstupanja s velikom vjerovatnoćom nadoknađuju.
. Dakle, aritmetička sredina velikog broja slučajnih varijabli već gubi svoj slučajni karakter i može se predvidjeti sa velikom preciznošću. Ovo se može objasniti činjenicom da su slučajna odstupanja vrijednosti X i od a i mogu biti različitih predznaka, te se stoga u zbiru ova odstupanja s velikom vjerovatnoćom nadoknađuju.
Terema Chebysheva (zakon velikih brojeva u obliku Čebiševa). Neka bude X 1 , X 2 , … , X n … je niz poparno nezavisnih slučajnih varijabli čije su varijanse ograničene na isti broj. Tada, bez obzira koliko mali broj ε uzmemo, vjerovatnoća nejednakosti
će biti proizvoljno blizu jedinice ako je broj n slučajne varijable da se uzimaju dovoljno velike. Formalno, to znači da pod uslovima teoreme
Ova vrsta konvergencije naziva se konvergencija u vjerovatnoći i označava se sa:
Dakle, Čebiševljev teorem kaže da ako postoji dovoljno veliki broj nezavisnih slučajnih varijabli, onda će njihova aritmetička sredina u jednom testu gotovo sigurno poprimiti vrijednost blizu prosjeka njihovih matematičkih očekivanja.
Najčešće se Čebiševljeva teorema primjenjuje u situaciji kada su slučajne varijable X 1 , X 2 , … , X n … imaju istu distribuciju (tj. isti zakon raspodjele ili istu gustinu vjerovatnoće). Zapravo, ovo je samo veliki broj instanci iste slučajne varijable.
Posljedica(o generalizovanoj Čebiševljevoj nejednakosti). Ako su nezavisne slučajne varijable X 1 , X 2 , … , X n … imaju istu distribuciju sa matematičkim očekivanjima M(X i )= a i disperzije D(X i )= D, onda
 , tj.
, tj.  .
.
Dokaz slijedi iz generalizirane Čebiševe nejednakosti prelaskom na granicu kao n→∞ .
Još jednom napominjemo da gore napisane jednakosti ne garantuju vrijednost količine  teži da ali at n→∞. Ova vrijednost je još uvijek slučajna varijabla, a njene pojedinačne vrijednosti mogu biti prilično daleko od ali. Ali vjerovatnoća takvog (daleko od toga ali) vrijednosti sa povećanjem n teži 0.
teži da ali at n→∞. Ova vrijednost je još uvijek slučajna varijabla, a njene pojedinačne vrijednosti mogu biti prilično daleko od ali. Ali vjerovatnoća takvog (daleko od toga ali) vrijednosti sa povećanjem n teži 0.
Komentar. Zaključak posljedice očito vrijedi i u opštijem slučaju kada su nezavisne slučajne varijable X 1 , X 2 , … , X n … imaju drugačiju distribuciju, ali ista matematička očekivanja (jednako ali) i varijanse ograničene u zbiru. Ovo omogućava da se predvidi tačnost merenja određene veličine, čak i ako se ta merenja vrše različitim instrumentima.
Razmotrimo detaljnije primenu ove posledice na merenje veličina. Hajde da koristimo neki uređaj n mjerenja iste količine, čija je prava vrijednost ali a mi ne znamo. Rezultati takvih mjerenja X 1
, X 2
, … , X n mogu se značajno razlikovati jedni od drugih (i od prave vrijednosti ali) zbog različitih nasumičnih faktora (pad tlaka, temperature, nasumične vibracije, itd.). Uzmite u obzir r.v. X- očitavanje instrumenta za jedno mjerenje veličine, kao i skup r.v. X 1
, X 2
, … , X n- očitavanje instrumenta pri prvom, drugom, ..., posljednjem mjerenju. Dakle, svaka od veličina X 1
, X 2
, … , X n
postoji samo jedan od primjera r.v. X, te stoga svi imaju istu distribuciju kao r.v. X. Budući da su rezultati mjerenja nezavisni jedan od drugog, r.v. X 1
, X 2
, … , X n može se smatrati nezavisnim. Ako uređaj ne daje sistematsku grešku (na primjer, nula nije "srušena" na skali, opruga nije rastegnuta itd.), onda možemo pretpostaviti da je matematičko očekivanje M(X) = a, i zbog toga M(X 1
) = ... = M(X n ) = a. Dakle, ispunjeni su uslovi gornjeg korolarca, i stoga, kao približna vrijednost količine ali možemo uzeti "implementaciju" slučajne varijable  u našem eksperimentu (koji se sastoji od niza n mjerenja), tj.
u našem eksperimentu (koji se sastoji od niza n mjerenja), tj.
 .
.
Uz veliki broj mjerenja, dobra tačnost proračuna pomoću ove formule je praktički pouzdana. Ovo je obrazloženje praktičnog principa da se kod velikog broja merenja njihova aritmetička sredina praktično ne razlikuje mnogo od prave vrednosti merene veličine.
Metoda "uzorkovanja", koja se široko koristi u matematičkoj statistici, temelji se na zakonu velikih brojeva, koji omogućava dobivanje njegovih objektivnih karakteristika s prihvatljivom točnošću iz relativno malog uzorka vrijednosti slučajne varijable. Ali o tome će biti riječi u sljedećem odjeljku.
Primjer. Na mjernom uređaju koji ne pravi sistematska izobličenja mjeri se određena količina ali jednom (primljena vrijednost X 1
), a zatim još 99 puta (dobivene vrijednosti X 2
, … , X 100
). Za pravu vrijednost mjerenja ali prvo uzmite rezultat prvog mjerenja  , a zatim aritmetičku sredinu svih mjerenja
, a zatim aritmetičku sredinu svih mjerenja  . Tačnost mjerenja uređaja je takva da standardna devijacija mjerenja σ nije veća od 1 (jer varijansa D=σ
2
takođe ne prelazi 1). Za svaku od metoda mjerenja procijenite vjerovatnoću da greška mjerenja neće preći 2.
. Tačnost mjerenja uređaja je takva da standardna devijacija mjerenja σ nije veća od 1 (jer varijansa D=σ
2
takođe ne prelazi 1). Za svaku od metoda mjerenja procijenite vjerovatnoću da greška mjerenja neće preći 2.
Rješenje. Neka r.v. X- očitavanje instrumenta za jedno mjerenje. Onda po uslovu M(X)=a. Da bismo odgovorili na ova pitanja, primjenjujemo generaliziranu Čebiševljevu nejednakost

za ε =2
prvo za n=1
a zatim za n=100
. U prvom slučaju dobijamo  , au drugom. Dakle, drugi slučaj praktično garantuje zadatu tačnost merenja, dok prvi ostavlja ozbiljne sumnje u tom smislu.
, au drugom. Dakle, drugi slučaj praktično garantuje zadatu tačnost merenja, dok prvi ostavlja ozbiljne sumnje u tom smislu.
Primijenimo gornje izjave na slučajne varijable koje nastaju u Bernoullijevoj shemi. Prisjetimo se suštine ove sheme. Neka se proizvede n nezavisni testovi, u svakom od kojih neki događaj ALI mogu se pojaviti sa istom vjerovatnoćom R, ali q=1–r(po značenju, ovo je vjerovatnoća suprotnog događaja - a ne pojava događaja ALI) . Hajde da potrošimo neki broj n takvi testovi. Uzmite u obzir slučajne varijable: X 1 – broj pojavljivanja događaja ALI in 1 th test, ..., X n– broj pojavljivanja događaja ALI in n th test. Svi uvedeni r.v. može poprimiti vrijednosti 0 ili 1 (događaj ALI može se pojaviti u testu ili ne) i vrijednost 1 uslovno prihvaćeno u svakom ispitivanju sa verovatnoćom str(vjerovatnoća nastanka događaja ALI u svakom testu) i vrijednost 0 sa vjerovatnoćom q= 1 – str. Stoga ove veličine imaju iste zakone raspodjele:
|
X 1 | ||
|
X n | ||
Stoga su prosječne vrijednosti ovih količina i njihove disperzije također iste: M(X 1 )=0 ∙ q+1 ∙ p= p, …, M(X n )= str ; D(X 1 )=(0 2 ∙ q+1 2 ∙ str)− str 2 = str∙(1− str)= str ∙ q, … , D(X n )= str ∙ q . Zamjenom ovih vrijednosti u generaliziranu Čebiševljevu nejednakost, dobivamo
 .
.
Jasno je da je r.v. X=X 1 +…+X n je broj pojavljivanja događaja ALI u svemu n suđenja (kako kažu - "broj uspjeha" u n testovi). Pustite u n test događaj ALI pojavio se u k Od njih. Tada se prethodna nejednakost može zapisati kao
 .
.
Ali veličina  , jednak omjeru broja pojavljivanja događaja ALI in n nezavisnih ispitivanja, na ukupan broj ispitivanja, prethodno nazvan relativna stopa događaja ALI in n testovi. Dakle, postoji nejednakost
, jednak omjeru broja pojavljivanja događaja ALI in n nezavisnih ispitivanja, na ukupan broj ispitivanja, prethodno nazvan relativna stopa događaja ALI in n testovi. Dakle, postoji nejednakost
 .
.
Prolaz sada do granice u n→∞, dobijamo  , tj.
, tj.  (prema vjerovatnoći). Ovo je sadržaj zakona velikih brojeva u obliku Bernoullija. Iz ovoga slijedi da za dovoljno veliki broj ispitivanja n proizvoljno mala odstupanja relativne frekvencije
(prema vjerovatnoći). Ovo je sadržaj zakona velikih brojeva u obliku Bernoullija. Iz ovoga slijedi da za dovoljno veliki broj ispitivanja n proizvoljno mala odstupanja relativne frekvencije  događaje iz njegove vjerovatnoće R su gotovo sigurni događaji, a velika odstupanja su gotovo nemoguća. Iz toga proizilazi zaključak o takvoj stabilnosti relativnih frekvencija (koju smo ranije nazvali eksperimentalničinjenica) opravdava prethodno uvedenu statističku definiciju vjerovatnoće događaja kao broja oko kojeg relativna učestalost događaja fluktuira.
događaje iz njegove vjerovatnoće R su gotovo sigurni događaji, a velika odstupanja su gotovo nemoguća. Iz toga proizilazi zaključak o takvoj stabilnosti relativnih frekvencija (koju smo ranije nazvali eksperimentalničinjenica) opravdava prethodno uvedenu statističku definiciju vjerovatnoće događaja kao broja oko kojeg relativna učestalost događaja fluktuira.
S obzirom da je izraz str∙
q=
str∙(1−
str)=
str−
str 2
ne prelazi interval izmene  (ovo je lako provjeriti pronalaženjem minimuma ove funkcije na ovom segmentu), iz gornje nejednakosti
(ovo je lako provjeriti pronalaženjem minimuma ove funkcije na ovom segmentu), iz gornje nejednakosti  lako to dobiti
lako to dobiti
 ,
,
koji se koristi za rješavanje odgovarajućih problema (jedan od njih će biti dat u nastavku).
Primjer. Novčić je bačen 1000 puta. Procijenite vjerovatnoću da će odstupanje relativne učestalosti pojavljivanja grba od njegove vjerovatnoće biti manje od 0,1.
Rješenje. Primjena nejednakosti  at str=
q=1/2
,
n=1000
,
ε=0,1, dobijamo .
at str=
q=1/2
,
n=1000
,
ε=0,1, dobijamo .
Primjer. Procijenite vjerovatnoću da, pod uslovima iz prethodnog primjera, broj k ispuštenih grbova bit će u rasponu od 400 prije 600 .
Rješenje. Stanje 400<
k<600
znači da 400/1000<
k/
n<600/1000
, tj. 0.4<
W n (A)<0.6
ili  . Kao što smo upravo vidjeli iz prethodnog primjera, vjerovatnoća takvog događaja je najmanje 0.975
.
. Kao što smo upravo vidjeli iz prethodnog primjera, vjerovatnoća takvog događaja je najmanje 0.975
.
Primjer. Za izračunavanje vjerovatnoće nekog događaja ALI Izvedeno je 1000 eksperimenata, u kojima je događaj ALI pojavio 300 puta. Procijenite vjerovatnoću da se relativna frekvencija (jednaka 300/1000=0,3) razlikuje od prave vjerovatnoće R ne više od 0,1.
Rješenje. Primjenjujući gornju nejednakost  za n=1000, ε=0.1, dobijamo .
za n=1000, ε=0.1, dobijamo .