Практика изучения случайных явлений показывает, что хотя результаты отдельных наблюдений, даже проведенных в одинаковых условиях, могут сильно отличаться, в то же время средние результаты для достаточно большого числа наблюдений устойчивы и слабо зависят от результатов отдельных наблюдений.
Теоретическим обоснованием этого замечательного свойства случайных явлений является закон больших чисел . Названием "закон больших чисел" объединена группа теорем, устанавливающих устойчивость средних результатов большого количества случайных явлений и объясняющих причину этой устойчивости.
Простейшая форма закона больших чисел, и исторически первая теорема этого раздела - теорема Бернулли , утверждающая, что если вероятность события одинакова во всех испытаниях, то с увеличением числа испытаний частота события стремится к вероятности события и перестает быть случайной.
Теорема Пуассона утверждает, что частота события в серии независимых испытаний стремится к среднему арифметическому его вероятностей и перестает быть случайной.
Предельные теоремы теории вероятностей, теоремы Муавра-Лапласа объясняют природу устойчивости частоты появлений события. Природа эта состоит в том, что предельным распределением числа появлений события при неограниченном возрастании числа испытаний (если вероятность события во всех испытаниях одинакова) является нормальное распределение.
Центральная предельная теорема объясняет широкое распространение нормального закона распределения. Теорема утверждает, что всегда, когда случайная величина образуется в результате сложения большого числа независимых случайных величин с конечными дисперсиями, закон распределения этой случайной величины оказывается практически нормальным законом.
Теорема, приведенная ниже под названием "Закон больших чисел " утверждает, что при определенных, достаточно общих, условиях, с увеличением числа случайных величин их среднее арифметическое стремится к среднему арифметическому математических ожиданий и перестает быть случайным.
Теорема Ляпунова объясняет широкое распространение нормального закона распределения и поясняет механизм его образования. Теорема позволяет утверждать, что всегда, когда случайная величина образуется в результате сложения большого числа независимых случайных величин, дисперсии которых малы по сравнению с дисперсией суммы, закон распределения этой случайной величины оказывается практически нормальным законом. А поскольку случайные величины всегда порождаются бесконечным количеством причин и чаще всего ни одна из них не имеет дисперсии, сравнимой с дисперсией самой случайной величины, то большинство встречающихся в практике случайных величин подчинено нормальному закону распределения.
В основе качественных и количественных утверждений закона больших чисел лежит неравенство Чебышева . Оно определяет верхнюю границу вероятности того, что отклонение значения случайной величины от ее математического ожидания больше некоторого заданного числа. Замечательно, что неравенство Чебышева дает оценку вероятности события для случайной величины, распределение которой неизвестно, известны лишь ее математическое ожидание и дисперсия.
Неравенство Чебышева. Если случайная
величина x
имеет дисперсию, то для
любого e
> 0 справедливо
неравенство ![]() , где M
x
и D
x
-
математическое ожидание и дисперсия случайной
величины x
.
, где M
x
и D
x
-
математическое ожидание и дисперсия случайной
величины x
.
Теорема Бернулли. Пусть m
n - число успехов в n испытаниях Бернулли и p -
вероятность успеха в отдельном испытании. Тогда
при любом e
> 0 справедливо ![]() .
.
Центральная предельная теорема. Если случайные величины x 1 , x 2 , …, x n , … попарно независимы, одинаково распределены и имеют конечную дисперсию, то при n ® равномерно по x (- ,)
БОЛЬШИХ ЧИСЕЛ ЗАКОН
общий принцип, в силу к-рого совместное случайных факторов приводит при нек-рых весьма общих условиях к результату, почти не зависящему от случая. Сближение частоты наступления случайного события с его вероятностью при возрастании числа испытаний (подмеченное сначала, по-видимому, на азартных играх) может служить первым примером действия этого принципа.
На рубеже 17 и 18 вв. Я. Бернулли доказал теорему, утверждающую, что в последовательности независимых испытаний, в каждом из к-рых наступления нек-рого события Аимеет одно и то же значение верно соотношение:
при любом - число появлений события в первых писпытаниях, - частота появлений. Эта Бернулли теорема
была распространена С. Пуассоном на случай последовательности независимых испытаний, где вероятность появления события Аможет зависеть от номера испытания. Пусть эта вероятность для k-го испытания равна и пусть
![]()
Тогда Пуассона теорема утверждает, что
при любом Первое строгое этой теоремы было дано П.
Л. Чебышевым (1846), метод к-рого полностью отличен от метода Пуассона и основан на нек-рых экстремальных соображениях; С. Пуассон выводил (2) из приближенной формулы для указанной вероятности, основанной на использовании закона Гаусса и в то время еще строго не обоснованной. У С. Пуассона впервые встречается и термин "закон больших чисел", к-рым он назвал свое обобщение теоремы Бернулли.
Естественное дальнейшее обобщение теорем Бернулли и Пуассона вознпкает, если заметить, что случайные величины можно представить в виде суммы
независимых случайных величин, где , если Апоявляется в А--м испытании, и
- в противном случае. При этом математич. ожидание (совпадающее со средним арифметическим математич. ожиданий ) равно рдля случая Бернулли и для случая Пуассона. Другими словами, в обоих случаях рассматривается отклонение среднего арифметического величин Х k
от среднего арифметического их математич. ожиданий.
В работе П. Л. Чебышева "О средних величинах" (1867) было установлено, что для независимых случайных величин соотношение
(при любом ) верно при весьма ^бщих предположениях. П. Л. Чебышев предполагал, что математич. ожидания все ограничены одной и той же постоянной, хотя из его доказательства видно, что достаточно требования ограниченности дисперсий
или даже требования
Таким образом, П. Л. Чебышев показал возможность широкого обобщения теоремы Бернулли. А. А. Марков отметил возможность дальнейших обобщений и предложил применять название Б. ч. з. ко всей совокупности обобщений теоремы Бернулли [и в частности, к (3)]. Метод Чебышева основан на точном установлении общих свойств математич. ожиданий и на использовании так наз. Чебышева неравенства
[для вероятности (3) оно дает оценку вида
![]()
эту границу можно заменить более точной, разумеется при более значительных ограничениях, см. Бернштейна неравенство
].
Последующие доказательства различных форм Б. ч. з. в той или иной степени являются развитием метода Чебышева. Применяя надлежащее "урезание" случайных величин (замену их вспомогательными величинами именно: , если где - нек-рые постоянные), А. А. Марков распространил Б. ч. з. на случаи, когда дисперсии слагаемых не существуют. Напр., он показал, что (3) имеет место, если при нек-рых постоянных ![]() и всех и
и всех и
Часть 1 - ГЛАВА 9. ЗАКОН БОЛЬШИХ ЧИСЕЛ. ПРЕДЕЛЬНЫЕ ТЕОРЕМЫ
При статистическом определениивероятности она трактуется как некоторое
число, к которому стремится относительная
частота случайного события. При
аксиоматическом определении вероятность –
это, по сути, аддитивная мера множества
исходов, благоприятствующих случайному
событию. В первом случае имеем дело с
эмпирическим пределом, во втором – с
теоретическим понятием меры. Совсем не
очевидно, что они относятся к одному и тому же
понятию. Связь разных определений
вероятности устанавливает теорема Бернулли,
являющаяся частным случаем закона больших
чисел. При увеличении числа испытаний
биномиальный закон стремится к
нормальному распределению. Это теорема
Муавра–Лапласа, которая является
частным случаем центральной предельной
теоремы. Последняя гласит, что функция
распределения суммы независимых
случайных величин с ростом числа
слагаемых стремится к нормальному
закону.
Закон больших чисел и центральная
предельная теорема лежат в основании
математической статистики.
9.1. Неравенство Чебышева
Пусть случайная величина ξ имеетконечные математическое ожидание
M[ξ] и дисперсию D[ξ]. Тогда для
любого положительного числа ε
справедливо неравенство:
Примечания
Для противоположного события:Неравенство Чебышева справедливо для
любого закона распределения.
Положив
факт:
, получаем нетривиальный
9.2. Закон больших чисел в форме Чебышева
Теорема Пусть случайные величиныпопарно независимы и имеют конечные
дисперсии, ограниченные одной и той же
постоянной
Тогда для
любого
имеем
Таким образом, закон больших чисел говорит о
сходимости по вероятности среднего арифметического случайных величин (т. е. случайной величины)
к среднему арифметическому их мат. ожиданий (т. е.
к не случайной величине).
9.2. Закон больших чисел в форме Чебышева: дополнение
Теорема (Маркова): закон большихчисел выполняется, если дисперсия
суммы случайных величин растет не
слишком быстро с ростом n:
10. 9.3. Теорема Бернулли
Теорема: Рассмотрим схему Бернулли.Пусть μn – число наступлений события А в
n независимых испытаниях, р – вероятность наступления события А в одном
испытании. Тогда для любого
Т.е. вероятность того, что отклонение
относительной частоты случайного события от
его вероятности р будет по модулю сколь угодно
мало, оно стремится к единице с ростом числа
испытаний n.
11.
Доказательство: Случайная величина μnраспределена по биномиальному закону, поэтому
имеем
12. 9.4. Характеристические функции
Характеристической функцией случайнойвеличины называется функция
где exp(x) = ex.
Таким образом,
представляет собой
математическое ожидание некоторой
комплексной случайной величины
связанной с величиной. В частности, если
– дискретная случайная величина,
заданная рядом распределения {xi, pi}, где i
= 1, 2,..., n, то
13.
Для непрерывной случайной величиныс плотностью распределения
вероятности
14.
15. 9.5. Центральная предельная теорема (теорема Ляпунова)
16.
Повторили пройденное17. ОСНОВЫ ТЕОРИИ ВЕРОЯТНОСТЕЙ И МАТЕМАТИЧЕСКОЙ СТАТИСТИКИ
ЧАСТЬ II. МАТЕМАТИЧЕСКАЯСТАТИСТИКА
18. Эпиграф
«Существует три вида лжи: ложь,наглая ложь и статистика»
Бенджамин Дизраэли
19. Введение
Две основные задачи математическойстатистики:
сбор и группировка статистических
данных;
разработка методов анализа
полученных данных в зависимости от
целей исследования.
20. Методы статистического анализа данных:
оценка неизвестной вероятности события;оценка неизвестной функции
распределения;
оценка параметров известного
распределения;
проверка статистических гипотез о виде
неизвестного распределения или о
значениях параметров известного
распределения.
21. ГЛАВА 1. ОСНОВНЫЕ ПОНЯТИЯ МАТЕМАТИЧЕСКОЙ СТАТИСТИКИ
22. 1.1. Генеральная совокупность и выборка
Генеральная совокупность - всемножество исследуемых объектов,
Выборка – набор объектов, случайно
отобранных из генеральной совокупности
для исследования.
Объем генеральной совокупности и
объем выборки - число объектов в генеральной совокупности и выборке - будем
обозначать соответственно как N и n.
23.
Выборка бывает повторной, когдакаждый отобранный объект перед
выбором следующего возвращается в
генеральную совокупность, и
бесповторной, если отобранный
объект в генеральную совокупность не
возвращается.
24. Репрезентативная выборка:
правильно представляет особенностигенеральной совокупности, т.е. является
репрезентативной (представительной).
По закону больших чисел, можно утверждать,
что это условие выполняется, если:
1) объем выборки n достаточно большой;
2) каждый объект выборки выбран случайно;
3) для каждого объекта вероятность попасть
в выборку одинакова.
25.
Генеральная совокупность и выборкамогут быть одномерными
(однофакторными)
и многомерными (многофакторными)
26. 1.2. Выборочный закон распределения (статистический ряд)
Пусть в выборке объемом nинтересующая нас случайная величина ξ
(какой-либо параметр объектов
генеральной совокупности) принимает n1
раз значение x1, n2 раза – значение x2,... и
nk раз – значение xk. Тогда наблюдаемые
значения x1, x2,..., xk случайной величины
ξ называются вариантами, а n1, n2,..., nk
– их частотами.
27.
Разность xmax – xmin есть размахвыборки, отношение ωi = ni /n –
относительная частота варианты xi.
Очевидно, что
28.
Если мы запишем варианты в возрастающем порядке, то получим вариационный ряд. Таблица, состоящая из такихупорядоченных вариант и их частот
(и/или относительных частот)
называется статистическим рядом или
выборочным законом распределения.
-- Аналог закона распределения дискретной
случайной величины в теории вероятности
29.
Если вариационный ряд состоит из оченьбольшого количества чисел или
исследуется некоторый непрерывный
признак, используют группированную
выборку. Для ее получения интервал, в
котором заключены все наблюдаемые
значения признака, разбивают на
несколько обычно равных частей
(подинтервалов) длиной h. При
составлении статистического ряда в
качестве xi обычно выбирают середины
подинтервалов, а ni приравнивают числу
вариант, попавших в i-й подинтервал.
30.
40- Частоты -
35
30
n2
n3
ns
n1
25
20
15
10
5
0
a
a+h/2 a+3h/2
- Варианты -
b-h/2
b
31. 1.3. Полигон частот, выборочная функция распределения
Отложим значения случайной величины xi пооси абсцисс, а значения ni – по оси ординат.
Ломаная линия, отрезки которой соединяют
точки с координатами (x1, n1), (x2, n2),..., (xk,
nk), называется полигоном
частот. Если вместо
абсолютных значений ni
на оси ординат отложить
относительные частоты ωi,
то получим полигон относительных частот
32.
По аналогии с функцией распределениядискретной случайной величины по
выборочному закону распределения можно
построить выборочную (эмпирическую)
функцию распределения
где суммирование выполняется по всем
частотам, которым соответствуют значения
вариант, меньшие x. Заметим, что
эмпирическая функция распределения
зависит от объема выборки n.
33.
В отличие от функции,найденной
для случайной величины ξ опытным
путем в результате обработки статистических данных, истинную функцию
распределения
,связанную с
генеральной совокупностью, называют
теоретической. (Обычно генеральная
совокупность настолько велика, что
обработать ее всю невозможно, т.е.
исследовать ее можно только
теоретически).
34.
Заметим, что:35. 1.4. Свойства эмпирической функции распределения
Ступенчатыйвид
36.
Еще одним графическим представлениеминтересующей нас выборки является
гистограмма – ступенчатая фигура,
состоящая из прямоугольников, основаниями которых служат подинтервалы
шириной h, а высотами – отрезки длиной
ni/h (гистограмма частот) или ωi/h
(гистограмма относительных частот).
В первом случае
площадь гистограммы равна объему
выборки n, во
втором – единице
37. Пример
38. ГЛАВА 2. ЧИСЛОВЫЕ ХАРАКТЕРИСТИКИ ВЫБОРКИ
39.
Задача математической статистики –по имеющейся выборке получить
информацию о генеральной
совокупности. Числовые характеристики репрезентативной выборки -оценка соответствующих характеристик
исследуемой случайной величины,
связанной с генеральной
совокупностью.
40. 2.1. Выборочное среднее и выборочная дисперсия, эмпирические моменты
Выборочным средним называетсясреднее арифметическое значений
вариант в выборке
Выборочное среднее используется для
статистической оценки математического
ожидания исследуемой случайной величины.
41.
Выборочной дисперсией называетсявеличина, равная
Выборочным средним квадратическим
отклонением –
42.
Легко показать, что выполняетсяследующее соотношение, удобное для
вычисления дисперсии:
43.
Другими характеристикамивариационного ряда являются:
мода M0 – варианта, имеющая
наибольшую частоту, и медиана me –
варианта, которая делит вариационный
ряд на две части, равные числу
вариант.
2, 5, 2, 11, 5, 6, 3, 13, 5 (мода = 5)
2, 2, 3, 5, 5, 5, 6, 11,13 (медиана = 5)
44.
По аналогии с соответствующимитеоретическими выражениями можно
построить эмпирические моменты,
применяемые для статистической
оценки начальных и центральных
моментов исследуемой случайной
величины.
45.
По аналогии с моментамитеории
вероятностей начальным эмпирическим
моментом порядка m называется величина
центральным эмпирическим моментом
порядка m -
46. 2.2. Свойства статистических оценок параметров распределения: несмещен-ность, эффективность, состоятельность
2.2. Свойства статистических оценокпараметров распределения: несмещенность, эффективность, состоятельность
После получения статистических оценок
параметров распределения случайной
величины ξ: выборочного среднего, выборочной дисперсии и т. д., необходимо убедиться,
что они являются хорошим приближением
для соответствующих параметров
теоретического распределения ξ.
Найдем условия, которые должны для этого
выполняться.
47.
48.
Статистическая оценка A* называетсянесмещенной, если ее математическое
ожидание равно оцениваемому параметру
генеральной совокупности A при любом
объеме выборки, т.е.
Если это условие не выполняется, оценка
называется смещенной.
Несмещенность оценки не является достаточным
условием хорошего приближения статистической
оценки A* к истинному (теоретическому) значению
оцениваемого параметра A.
49.
Разброс отдельных значенийотносительно среднего значения M
зависит от величины дисперсии D.
Если дисперсия велика, то значение
найденное по данным одной выборки,
может значительно отличаться от
оцениваемого параметра.
Следовательно, для надежного
оценивания дисперсия D должна
быть мала. Статистическая оценка
называется эффективной, если при
заданном объеме выборки n она имеет
наименьшую возможную дисперсию.
50.
К статистическим оценкампредъявляется еще требование
состоятельности. Оценка называется
состоятельной, если при n → она
стремится по вероятности к
оцениваемому параметру. Заметим, что
несмещенная оценка будет
состоятельной, если при n → ее
дисперсия стремится к 0.
51. 2.3. Свойства выборочного среднего
Будем полагать, что варианты x1, x2,..., xnявляются значениями соответствующих
независимых одинаково распределенных случайных величин
,
имеющих математическое ожидание
и дисперсию
. Тогда
выборочное среднее можно
рассматривать как случайную величину
52.
Несмещенность. Из свойствматематического ожидания следует, что
т.е. выборочное среднее является
несмещенной оценкой математического
ожидания случайной величины.
Можно также показать эффективность
оценки по выборочному среднему математического ожидания (для нормального
распределения)
53.
Состоятельность. Пусть a – оцениваемыйпараметр, а именно математическое
ожидание генеральной совокупности
– дисперсия генеральной совокупности
.
Рассмотрим неравенство Чебышева
У нас:
тогда
. При n → правая часть
неравенства стремится к нулю для любого ε > 0, т.е.
и, следовательно, величина X, представляющая выборочную
оценку, стремится к оцениваемому параметру a по вероятности.
54.
Таким образом, можно сделать вывод,что выборочное среднее является
несмещенной, эффективной (по
крайней мере, для нормального
распределения) и состоятельной
оценкой математического ожидания
случайной величины, связанной с
генеральной совокупностью.
55.
56.
ЛЕКЦИЯ 657. 2.4. Свойства выборочной дисперсии
Исследуем несмещенность выборочной дисперсии D* какоценки дисперсии случайной величины
58.
59.
60. Пример
Найти выборочное среднее, выборочнуюдисперсию и среднее квадратическое
отклонение, моду и исправленную выборочную
дисперсию для выборки, имеющей следующий
закон распределения:
Решение:
61.
62. ГЛАВА 3. ТОЧЕЧНОЕ ОЦЕНИВАНИЕ ПАРАМЕТРОВ ИЗВЕСТНОГО РАСПРЕДЕЛЕНИЯ
63.
Будем считать, что общий вид законараспределения нам известен и
остается уточнить детали –
параметры, определяющие его
действительную форму. Существует
несколько методов решения этой
задачи, два из которых мы
рассмотрим: метод моментов и метод
наибольшего правдоподобия
64. 3.1. Метод моментов
65.
Метод моментов, развитый КарломПирсоном в 1894 г., основан на
использовании этих приближенных равенств:
моменты
рассчитываются
теоретически по известному закону
распределения с параметрами θ, а
выборочные моменты
вычисляются
по имеющейся выборке. Неизвестные
параметры
определяются в
результате решения системы из r уравнений,
связывающих соответствующие
теоретический и эмпирический моменты,
например,
.
66.
Можно показать, что оценкипараметров θ, полученные методом
моментов, состоятельны, их
математические ожидания отличаются
от истинных значений параметров на
величину порядка n–1, а средние
квадратические отклонения являются
величинами порядка n–0,5
67. Пример
Известно, что характеристика ξ объектовгенеральной совокупности, являясь случайной
величиной, имеет равномерное распределение, зависящее от параметров a и b:
Требуется определить методом моментов
параметры a и b по известному выборочному
среднему
и выборочной дисперсии
68. Напоминание
α1 – мат.ожидание β2 - дисперсия69.
(*)70.
71. 3.2. Метод наибольшего правдоподобия
В основе метода лежит функция правдоподобияL(x1, x2,..., xn, θ), являющаяся законом
распределения вектора
, где
случайные величины
принимают значения
вариант выборки, т.е. имеют одинаковое
распределение. Поскольку случайные величины
независимы, функция правдоподобия имеет вид:
72.
Идея метода наибольшегоправдоподобия состоит в том, что мы
ищем такие значения параметров θ, при
которых вероятность появления в
выборке значений вариант x1, x2,..., xn
является наибольшей. Иными словами,
в качестве оценки параметров θ
берется вектор,при котором функция
правдоподобия имеет локальный
максимум при заданных x1, x2, …, xn:
73.
Оценки по методу максимальногоправдоподобия получаются из
необходимого условия экстремума
функции L(x1,x2,..., xn,θ) в точке
74. Примечания:
1. При поиске максимума функции правдоподобиядля упрощения расчетов можно выполнить
действия, не изменяющие результата: во-первых,
использовать вместо L(x1, x2,..., xn,θ) логарифмическую функцию правдоподобия l(x1, x2,..., xn,θ) =
ln L(x1, x2,..., xn,θ); во-вторых, отбросить в выражении
для функции правдоподобия не зависящие от θ
слагаемые (для l) или положительные
сомножители (для L).
2. Оценки параметров, рассмотренные нами,
можно назвать точечными оценками, так как для
неизвестного параметра θ определяется одна
единственная точка
, являющаяся его
приближенным значением. Однако такой подход
может приводить к грубым ошибкам, и точечная
оценка может значительно отличаться от истинного
значения оцениваемого параметра (особенно в
случае выборки малого объема).
75. Пример
Решение. В данной задаче следует оценитьдва неизвестных параметра: a и σ2.
Логарифмическая функция правдоподобия
имеет вид
76.
Отбросив в этой формуле слагаемое, которое независит от a и σ2, составим систему уравнений
правдоподобия
Решая, получаем:
77. ГЛАВА 4. ИНТЕРВАЛЬНОЕ ОЦЕНИВАНИЕ ПАРАМЕТРОВ ИЗВЕСТНОГО РАСПРЕДЕЛЕНИЯ
78.
(*)
79.
(*)80. 4.1. Оценивание математического ожидания нормально распределенной величины при известной дисперсии
выборочное среднее
как значение случайной
81.
Имеем:(1)
(2)
82.
(2)(1)
(*)
(*)
83. 4.2. Оценивание математического ожидания нормально распределенной величины при неизвестной дисперсии
84.
степенями свободы. Плотность
величины есть
85.
86. Плотность распределения Стьюдента c n – 1 степенями свободы
87.
88.
89.
находить по формулам
90. 4.3. Оценивание среднего квадратического отклонения нормально распределенной величины
отклонением σ.
неизвестным математическим
ожиданием.
91. 4.3.1. Частный случай известного математического ожидания
Используя величины
,
выборочной дисперсии D*:
92.
величины
имеют нормальное
93.
условия
где
– плотность распределения χ2
94.
95.
96.
97. 4.3.2. Частный случай неизвестного математического ожидания
(где случайная величина
χ2 с n–1 степенями свободы.
98.
99. 4.4. Оценивание математического ожидания случайной величины для произвольной выборки
выборке большого объема (n >> 1).
100.
величин
, имеющих
дисперсию
, а полученное
выборочное среднее
как значение
случайной величины
величина
имеет асимптотически
.
101.
использовать формулу
102.
103.
Лекция 7104.
Повторение пройденного105. ГЛАВА 4. ИНТЕРВАЛЬНОЕ ОЦЕНИВАНИЕ ПАРАМЕТРОВ ИЗВЕСТНОГО РАСПРЕДЕЛЕНИЯ
106.
Задачу оценивания параметра известногораспределения можно решать путем
построения интервала, в который с заданной
вероятностью попадает истинное значение
параметра. Такой метод оценивания
называется интервальной оценкой.
Обычно в математике для оценки
параметра θ строится неравенство
(*)
где число δ характеризует точность оценки:
чем меньше δ, тем лучше оценка.
107.
(*)108. 4.1. Оценивание математического ожидания нормально распределенной величины при известной дисперсии
Пусть исследуемая случайная величина ξ распределена по нормальному закону с известнымсредним квадратическим отклонением σ и
неизвестным математическим ожиданием a.
Требуется по значению выборочного среднего
оценить математическое ожидание ξ.
Как и ранее, будем рассматривать получаемое
выборочное среднее
как значение случайной
величины, а значения вариант выборки x1, x2, …,
xn – соответственно как значения одинаково
распределенных независимых случайных величин
, каждая из которых имеет мат. ожидание a и среднее квадратическое отклонение σ.
109.
Имеем:(1)
(2)
110.
(2)(1)
(*)
(*)
111. 4.2. Оценивание математического ожидания нормально распределенной величины при неизвестной дисперсии
112.
Известно, что случайная величина tn,заданная таким образом, имеет
распределение Стьюдента с k = n – 1
степенями свободы. Плотность
распределения вероятностей такой
величины есть
113.
114. Плотность распределения Стьюдента c n – 1 степенями свободы
115.
116.
117.
Примечание. При большом числе степенейсвободы k распределение Стьюдента
стремится к нормальному распределению с
нулевым математическим ожиданием и
единичной дисперсией. Поэтому при k ≥ 30
доверительный интервал можно на практике
находить по формулам
118. 4.3. Оценивание среднего квадратического отклонения нормально распределенной величины
Пусть исследуемая случайная величинаξ распределена по нормальному закону
с математическим ожиданием a и
неизвестным средним квадратическим
отклонением σ.
Рассмотрим два случая: с известным и
неизвестным математическим
ожиданием.
119. 4.3.1. Частный случай известного математического ожидания
Пусть известно значение M[ξ] = a и требуетсяоценить только σ или дисперсию D[ξ] = σ2.
Напомним, что при известном мат. ожидании
несмещенной оценкой дисперсии является
выборочная дисперсия D* = (σ*)2
Используя величины
,
определенные выше, введем случайную
величину Y, принимающую значения
выборочной дисперсии D*:
120.
Рассмотрим случайную величинуСтоящие под знаком суммы случайные
величины
имеют нормальное
распределение с плотностью fN (x, 0, 1).
Тогда Hn имеет распределение χ2 с n
степенями свободы как сумма квадратов n
независимых стандартных (a = 0, σ = 1)
нормальных случайных величин.
121.
Определим доверительный интервал изусловия
где
– плотность распределения χ2
и γ – надежность (доверительная
вероятность). Величина γ численно равна
площади заштрихованной фигуры на рис.
122.
123.
124.
125. 4.3.2. Частный случай неизвестного математического ожидания
На практике чаще всего встречается ситуация,когда неизвестны оба параметра нормального
распределения: математическое ожидание a и
среднее квадратическое отклонение σ.
В этом случае построение доверительного
интервала основывается на теореме Фишера, из
кот. следует, что случайная величина
(где случайная величина
принимающая значения несмещенной
выборочной дисперсии s2, имеет распределение
χ2 с n–1 степенями свободы.
126.
127. 4.4. Оценивание математического ожидания случайной величины для произвольной выборки
Интервальные оценки математическогоожидания M[ξ], полученные для нормально
распределенной случайной величины ξ ,
являются, вообще говоря, непригодными для
случайных величин, имеющих иной вид
распределения. Однако есть ситуация, когда
для любых случайных величин можно
пользоваться подобными интервальными
соотношениями, – это имеет место при
выборке большого объема (n >> 1).
128.
Как и выше, будем рассматривать вариантыx1, x2,..., xn как значения независимых,
одинаково распределенных случайных
величин
, имеющих
математическое ожидание M[ξi] = mξ и
дисперсию
, а полученное
выборочное среднее
как значение
случайной величины
Согласно центральной предельной теореме
величина
имеет асимптотически
нормальный закон распределения c
математическим ожиданием mξ и дисперсией
.
129.
Поэтому, если известно значение дисперсиислучайной величины ξ, то можно
пользоваться приближенными формулами
Если же значение дисперсии величины ξ
неизвестно, то при больших n можно
использовать формулу
где s – исправленное ср.-кв. отклонение
130.
Повторили пройденное131. ГЛАВА 5. ПРОВЕРКА СТАТИСТИЧЕСКИХ ГИПОТЕЗ
132.
Статистической гипотезой называют гипотезу овиде неизвестного распределения или о параметрах
известного распределения случайной величины.
Проверяемая гипотеза, обозначаемая обычно как
H0, называется нулевой или основной гипотезы.
Дополнительно используемая гипотеза H1,
противоречащая гипотезе H0, называется
конкурирующей или альтернативной.
Статистическая проверка выдвинутой нулевой
гипотезы H0 состоит в ее сопоставлении с
выборочными данными. При такой проверке
возможно появление ошибок двух видов:
а) ошибки первого рода – случаи, когда отвергается
правильная гипотеза H0;
б) ошибки второго рода – случаи, когда
принимается неверная гипотеза H0.
133.
Вероятность ошибки первого рода будемназывать уровнем значимости и обозначать
как α.
Основной прием проверки статистических
гипотез заключается в том, что по
имеющейся выборке вычисляется значение
статистического критерия – некоторой
случайной величины T, имеющей известный
закон распределения. Область значений T,
при которых основная гипотеза H0 должна
быть отвергнута, называют критической, а
область значений T, при которых эту гипотезу
можно принять, – областью принятия
гипотезы.
134.
135. 5.1. Проверка гипотез о параметрах известного распределения
5.1.1. Проверка гипотезы о математическоможидании нормально распределенной случайной
величины
Пусть случайная величина ξ имеет
нормальное распределение.
Требуется проверить предположение о том,
что ее математическое ожидание равно
некоторому числу a0. Рассмотрим отдельно
случаи, когда дисперсия ξ известна и когда
она неизвестна.
136.
В случае известной дисперсии D[ξ] = σ2,как и в п. 4.1, определим случайную
величину, принимающую значения
выборочного среднего. Гипотеза H0
изначально формулируется как M[ξ] =
a0. Поскольку выборочное среднее
является несмещенной оценкой M[ξ], то
гипотезу H0 можно представить как
137.
Учитывая несмещенность исправленныхвыборочных дисперсий, нулевую гипотезу можно
записать следующим образом:
где случайная величина
принимает значения исправленной выборочной
дисперсии величины ξ и аналогична случайной
величине Z, рассмотренной в п. 4.2.
В качестве статистического критерия выберем
случайную величину
принимающую значение отношения бóльшей
выборочной дисперсии к меньшей.
145.
Случайная величина F имеетраспределение Фишера – Снедекора с
числом степеней свободы k1 = n1 – 1 и k2
= n2 – 1, где n1 – объем выборки, по
которой вычислена бóльшая
исправленная дисперсия
, а n2 –
объем второй выборки, по которой
найдена меньшая дисперсия.
Рассмотрим два вида конкурирующих
гипотез
146.
147.
148. 5.1.3. Сравнение математических ожиданий независимых случайных величин
Сначала рассмотрим случай нормальногораспределения случайных величин с известными
дисперсиями, а затем на его основе – более общий
случай произвольного распределения величин при
достаточно больших независимых выборках.
Пусть случайные величины ξ1 и ξ2 независимы и
распределены нормально, и пусть их дисперсии D[ξ1]
и D[ξ2] известны. (Например, они могут быть найдены
из какого-то другого опыта или рассчитаны
теоретически). Извлечены выборки объемом n1 и n2
соответственно. Пусть
– выборочные
средние для этих выборок. Требуется по выборочным
средним при заданном уровне значимости α
проверить гипотезу о равенстве математических
ожиданий рассматриваемых случайных величин сделать из априорных соображений,
основываясь на условиях эксперимента, и
тогда предположения о параметрах
распределения исследуются, как показано
ранее. Однако весьма часто возникает
необходимость проверить выдвинутую
гипотезу о законе распределения.
Статистические критерии, предназначенные
для таких проверок, обычно называются
критериями согласия.
154.
Известно несколько критериев согласия. Достоинствомкритерия Пирсона является его универсальность. С его
помощью можно проверять гипотезы о различных
законах распределения.
Критерий Пирсона основан на сравнении частот,
найденных по выборке (эмпирических частот), с
частотами, рассчитанными с помощью проверяемого
закона распределения (теоретическими частотами).
Обычно эмпирические и теоретические частоты
различаются. Следует выяснить, случайно ли
расхождение частот или оно значимо и объясняется
тем, что теоретические частоты вычислены исходя из
неверной гипотезы о распределении генеральной
совокупности.
Критерий Пирсона, как и любой другой, отвечает на
вопрос, есть ли согласие выдвинутой гипотезы с
эмпирическими данными при заданном уровне
значимости.
155. 5.2.1. Проверка гипотезы о нормальном распределении
Пусть имеется случайная величина ξ и сделанавыборка достаточно большого объема n с большим
количеством различных значений вариант. Требуется
при уровне значимости α проверить нулевую гипотезу
H0 о том, что случайная величина ξ распределена
нормально.
Для удобства обработки выборки возьмем два числа
α и β:
и разделим интервал [α, β] на s
подинтервалов. Будем считать, что значения вариант,
попавших в каждый подинтервал,приближенно равны
числу, задающему середину подинтервала.
Подсчитав число вариант, попавших в каждый Квантилью порядка α (0 < α < 1) непрерывной
случайной величины ξ называется такое число xα,
для которого выполняется равенство
.
Квантиль x½ называется медианой случайной
величины ξ, квантили x¼ и x¾ – ее квартилями, a
x0,1, x0,2,..., x0,9 – децилями.
Для стандартного нормального распределения (a =
0, σ = 1) и, следовательно,
где FN (x, a, σ) – функция распределения нормально
распределенной случайной величины, а Φ(x) –
функция Лапласа.
Квантиль стандартного нормального распределения
xα для заданного α можно найти из соотношения
162. 6.2. Распределение Стьюдента
Если– независимые
случайные величины, имеющие
нормальное распределение с нулевым
математическим ожиданием и
единичной дисперсией, то
распределение случайной величины
называют распределением Стьюдента
с n степенями свободы (W.S. Gosset).
Зако́н больши́х чи́сел в теории вероятностей утверждает, что эмпирическое среднее (среднее арифметическое) достаточно большой конечной выборки из фиксированного распределения близко к теоретическому среднему (математическому ожиданию) этого распределения. В зависимости от вида сходимости различают слабый закон больших чисел, когда имеет место сходимость по вероятности , и усиленный закон больших чисел, когда имеет место сходимость почти всюду .
Всегда найдётся такое конечное число испытаний, при котором с любой заданной наперёд вероятностью меньше 1 относительная частота появления некоторого события будет сколь угодно мало отличаться от его вероятности.
Общий смысл закона больших чисел: совместное действие большого числа одинаковых и независимых случайных факторов приводит к результату, в пределе не зависящему от случая.
На этом свойстве основаны методы оценки вероятности на основе анализа конечной выборки. Наглядным примером является прогноз результатов выборов на основе опроса выборки избирателей.
Энциклопедичный YouTube
1 / 5
✪ Закон больших чисел
✪ 07 - Теория вероятностей. Закон больших чисел
✪ 42 Закон больших чисел
✪ 1 - Закон больших чисел Чебышёва
✪ 11 класс, 25 урок, Гауссова кривая. Закон больших чисел
Субтитры
Давайте разберем закон больших чисел, который является, пожалуй, самым интуитивным законом в математике и теории вероятностей. И поскольку он применим ко многим вещам, его иногда используют и понимают неправильно. Давайте я вначале для точности дам ему определение, а потом уже мы поговорим об интуиции. Возьмем случайную величину, например Х. Допустим, мы знаем ее математическое ожидание или среднее для совокупности. Закон больших чисел просто говорит, что, если мы возьмем пример n-ого количества наблюдений случайной величины и выведем среднее число всех этих наблюдений… Давайте возьмем переменную. Назовем ее Х с нижним индексом n и с чертой наверху. Это среднее арифметическое n-ого количества наблюдений нашей случайной величины. Вот мое первое наблюдение. Я провожу эксперимент один раз и делаю это наблюдение, затем я провожу его еще раз и делаю вот это наблюдение, я провожу его снова и получаю вот это. Я провожу этот эксперимент n-ое количество раз, а затем делю на количество моих наблюдений. Вот мое выборочное среднее значение. Вот среднее значение всех наблюдений, которые я сделала. Закон больших чисел говорит нам, что мое выборочное среднее будет приближаться к математическому ожиданию случайной величины. Либо я могу также написать, что мое выборочное среднее будет приближаться к среднему по совокупности для n-ого количества, стремящегося к бесконечности. Я не буду четко разделять понятия «приближение» и «сходимость», но надеюсь, вы интуитивно понимаете, что, если я возьму довольно большую выборку здесь, то я получу математическое ожидание для совокупности в целом. Думаю, большинство из вас интуитивно понимает, что, если я сделаю достаточное количество испытаний с большой выборкой примеров, в конце концов, испытания дадут мне ожидаемые мною значения, принимая во внимание математическое ожидание, вероятность и все такое прочее. Но, я думаю, часто бывает непонятно, почему так происходит. И прежде, чем я начну объяснять, почему это так, давайте я приведу конкретный пример. Закон больших чисел говорит нам, что... Допустим, у нас есть случайная величина Х. Она равна количеству орлов при 100 подбрасываниях правильной монеты. Прежде всего, мы знаем математическое ожидание этой случайной величины. Это количество подбрасываний монеты или испытаний, умноженное на шансы успеха любого испытания. Значит, это равно 50-ти. То есть, закон больших чисел говорит, что, если мы возьмем выборку, или если я приведу к среднему значению эти испытания, я получу... В первый раз, когда я провожу испытание, я подбрасываю монету 100 раз или возьму ящик с сотней монет, тряхну его, а потом сосчитаю, сколько у меня выпадет орлов, и получу, допустим, число 55. Это будет Х1. Затем я снова встряхну ящик и получу число 65. Затем еще раз – и получу 45. И я проделываю это n-ое количество раз, а затем делю это на количество испытаний. Закон больших чисел говорит нам, что это среднее (среднее значение всех моих наблюдений) будет стремиться к 50-ти в то время, как n будет стремиться к бесконечности. Теперь я бы хотела немного поговорить о том, почему так происходит. Многие считают, что если после 100 испытаний, у меня результат выше среднего, то по законам вероятности у меня должно выпасть больше или меньше орлов для того, чтобы, так сказать, компенсировать разницу. Это не совсем то, что произойдет. Это часто называют «заблуждением азартного игрока». Давайте я покажу различие. Я буду использовать следующий пример. Давайте я изображу график. Поменяем цвет. Это n, моя ось Х – это n. Это количество испытаний, которые я проведу. А моя ось Y будет выборочным средним. Мы знаем, что математическое ожидание этой произвольной переменной равно 50-ти. Давайте я это нарисую. Это 50. Вернемся к нашему примеру. Если n равно… Во время моего первого испытания я получила 55, это мое среднее значение. У меня только одна точка ввода данных. Затем, после двух испытаний, я получаю 65. Значит, мое среднее значение будет 65+55, деленное на 2. Это 60. И мое среднее значение немного возросло. Затем я получила 45, что вновь снизило мое среднее арифметическое. Я не буду наносить на графике 45. Теперь мне нужно привести все это к среднему значению. Чему равно 45+65? Давайте я вычислю это значение, чтобы обозначить точку. Это 165 делить на 3. Это 53. Нет, 55. Значит, среднее значение снова опускается до 55-ти. Мы можем продолжить эти испытания. После того, как мы проделали три испытания и получили это среднее, многие люди думают, что боги вероятности сделают так, что у нас выпадет меньше орлов в будущем, что в следующих нескольких испытаниях результаты будут ниже, чтобы уменьшить среднее значение. Но это не всегда так. В дальнейшем вероятность всегда остается такой же. Вероятность того, что у меня выпадет орел, всегда будет 50-ти %. Не то, что у меня изначально выпадает определенное количество орлов, большее, чем я ожидаю, а дальше внезапно должны выпасть решки. Это «заблуждение игрока». Если у вас выпадает несоразмерно большое количество орлов, это не значит, что в определенный момент у вас начнет выпадать несоразмерно большое количество решек. Это не совсем так. Закон больших чисел говорит нам, что это не имеет значения. Допустим, после определенного конечного количества испытаний, ваше среднее... Вероятность этого достаточно мала, но, тем не менее... Допустим, ваше среднее достигло этой отметки – 70-ти. Вы думаете: «Ого, мы основательно отошли от математического ожидания». Но закон больших чисел говорит, что ему все равно, сколько испытаний мы провели. У нас все равно осталось бесконечное количество испытаний впереди. Математическое ожидание этого бесконечного количества испытаний, особенно в подобной ситуации, будет следующим. Когда вы приходите к конечному числу, которое выражает какое-нибудь большое значение, бесконечное число, которое сойдется с ним, снова приведет к математическому ожиданию. Это, конечно, очень свободное толкование, но это то, что говорит нам закон больших чисел. Это важно. Он не говорит нам, что, если у нас выпало много орлов, то каким-то образом вероятность выпадения решки увеличится, чтобы это компенсировать. Этот закон говорит нам, что неважно, каков результат при конечном количестве испытаний, если у вас еще осталось бесконечное количество испытаний впереди. И если вы сделаете достаточное их количество, вы вернетесь снова к математическому ожиданию. Это важный момент. Подумайте о нем. Но это не используется ежедневно на практике с лотереями и в казино, хотя известно, что, если вы сделаете достаточное количество испытаний... Мы даже можем это посчитать... чему равна вероятность того, что мы серьезно отклонимся от нормы? Но казино и лотереи каждый день работают по тому принципу, что если взять достаточное количество людей, естественно, за короткий срок, с небольшой выборкой, то несколько человек сорвут куш. Но за большой срок казино всегда останется в выигрыше из-за параметров игр, в которые они приглашают вас играть. Это важный принцип вероятности, который является интуитивным. Хотя иногда, когда вам его формально объясняют со случайными величинами, все это выглядит немного запутанно. Все, что этот закон говорит, – это что чем больше выборок, тем больше среднее арифметическое этих выборок будет стремиться к истинному среднему. А если быть более конкретной, то среднее арифметическое вашей выборки сойдется с математическим ожиданием случайной величины. Вот и все. До встречи в следующем видео!
Слабый закон больших чисел
Слабый закон больших чисел также называется теоремой Бернулли , в честь Якоба Бернулли , доказавшего его в 1713 году .
Пусть есть бесконечная последовательность (последовательное перечисление) одинаково распределённых и некоррелированных случайных величин . То есть их ковариация c o v (X i , X j) = 0 , ∀ i ≠ j {\displaystyle \mathrm {cov} (X_{i},X_{j})=0,\;\forall i\not =j} . Пусть . Обозначим через выборочное среднее первых n {\displaystyle n} членов:
.
Тогда X ¯ n → P μ {\displaystyle {\bar {X}}_{n}\to ^{\!\!\!\!\!\!\mathbb {P} }\mu } .
То есть для всякого положительного ε {\displaystyle \varepsilon }
lim n → ∞ Pr (| X ¯ n − μ | < ε) = 1. {\displaystyle \lim _{n\to \infty }\Pr \!\left(\,|{\bar {X}}_{n}-\mu |<\varepsilon \,\right)=1.}Усиленный закон больших чисел
Пусть есть бесконечная последовательность независимых одинаково распределённых случайных величин { X i } i = 1 ∞ {\displaystyle \{X_{i}\}_{i=1}^{\infty }} , определённых на одном вероятностном пространстве (Ω , F , P) {\displaystyle (\Omega ,{\mathcal {F}},\mathbb {P})} . Пусть E X i = μ , ∀ i ∈ N {\displaystyle \mathbb {E} X_{i}=\mu ,\;\forall i\in \mathbb {N} } . Обозначим через X ¯ n {\displaystyle {\bar {X}}_{n}} выборочное среднее первых n {\displaystyle n} членов:
X ¯ n = 1 n ∑ i = 1 n X i , n ∈ N {\displaystyle {\bar {X}}_{n}={\frac {1}{n}}\sum \limits _{i=1}^{n}X_{i},\;n\in \mathbb {N} } .Тогда X ¯ n → μ {\displaystyle {\bar {X}}_{n}\to \mu } почти всегда.
Pr (lim n → ∞ X ¯ n = μ) = 1. {\displaystyle \Pr \!\left(\lim _{n\to \infty }{\bar {X}}_{n}=\mu \right)=1.} .Как и любой математический закон, закон больших чисел может быть применим к реальному миру только при известных допущениях, которые могут выполняться лишь с некоторой степенью точности. Так, например, условия последовательных испытаний часто не могут сохраняться бесконечно долго и с абсолютной точностью . Кроме того, закон больших чисел говорит лишь о невероятности значительного отклонения среднего значения от математического ожидания .
Слова о больших числах относятся к числу испытаний – рассматривается большое число значений случайной величины или совокупное действие большого числа случайных величин. Суть этого закона состоит в следующем: хотя невозможно предсказать, какое значение в единичном эксперименте примет отдельная случайная величина, однако, суммарный результат действия большого числа независимых случайных величин утрачивает случайный характер и может быть предсказан практически достоверно (т.е. с большой вероятностью). Например, невозможно предсказать, какой стороной упадет одна монета. Однако если подбросить 2 тонны монет, то с большой уверенностью можно утверждать, что вес монет, упавших гербом вверх, равен 1 тонне.
К закону больших чисел прежде всего относится так называемое неравенство Чебышева, которое оценивает в отдельном испытании вероятность принятия случайной величиной значения, уклоняющееся от среднего значения не более, чем на заданное значение.
Неравенство Чебышева . Пусть Х – произвольная случайная величина, а=М(Х ) , а D (X ) – ее дисперсия. Тогда
Пример . Номинальное (т.е. требуемое) значение диаметра вытачиваемой на станке втулки равно 5мм , а дисперсия не более 0.01 (таков допуск точности станка). Оценить вероятность того, что при изготовлении одной втулки отклонение ее диаметра от номинального окажется менее 0.5мм .
Решение. Пусть с.в. Х – диаметр изготовленной втулки. По условию ее математическое ожидание равно номинальному диаметру (если нет систематического сбоя в настройке станка) : а=М(Х )=5 , а дисперсия D (Х)≤0.01 . Применяя неравенство Чебышева при ε = 0.5 , получим:
Таким образом, вероятность такого отклонения достаточно велика, а потому можно сделать вывод о том, что при единичном изготовлении детали практически наверняка отклонение диаметра от номинального не превзойдет 0.5мм .
По своему смыслу среднее квадратическое отклонение σ характеризует среднее отклонение случайной величины от своего центра (т.е. от своего математического ожидания). Поскольку это среднее отклонение, то при испытании возможны и большие (ударение на о) отклонения. Насколько же большие отклонения практически возможны? При изучении нормально распределенных случайных величин мы вывели правило «трех сигм»: нормально распределенная случайная величина Х при единичном испытании практически не отклоняется от своего среднего далее, чем на 3σ , где σ= σ(Х) – среднее квадратическое отклонение с.в. Х . Такое правило мы вывели из того, что получили неравенство
 .
.
Оценим теперь вероятность для произвольной случайной величины Х принять значение, отличающееся от среднего не более чем на утроенное среднее квадратическое отклонение. Применяя неравенство Чебышева при ε = 3σ и учитывая, что D (Х)= σ 2 , получаем:
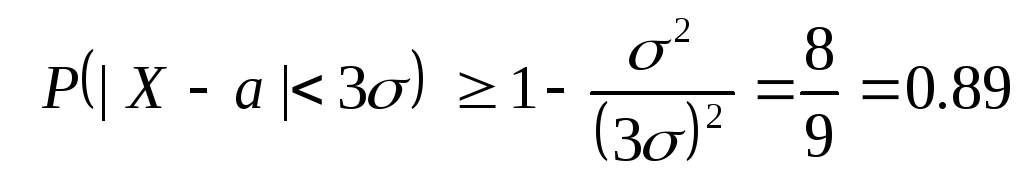 .
.
Таким образом, в общем случае вероятность отклонения случайной величины от своего среднего не более чем на три средних квадратичных отклонения мы можем оценить числом 0.89 , в то время как для именно нормального распределения можно гарантировать это с вероятностью 0.997 .
Неравенство Чебышева может быть обобщено на систему независимых одинаково распределенных случайных величин.
Обобщенное неравенство Чебышева . Если независимые случайные величины Х 1 , Х 2 , … , Х n M (X i )= a и дисперсиями D (X i )= D , то
При n =1 это неравенство переходит в неравенство Чебышева, сформулированное выше.
Неравенство Чебышева, имея самостоятельное значение для решения соответствующих задач, применяется для доказательства так называемой теоремы Чебышева. Мы с начала расскажем о сути этой теоремы, а затем дадим ее формальную формулировку.
Пусть
Х
1
,
Х
2
,
… , Х
n
– большое число независимых случайных
величин с математическими ожиданиями
М(Х
1
)=а
1
,
… , М(Х
n
)=а
n
. Хотя каждая из них в результате
эксперимента может принять значение,
далекое от своего среднего (т.е.
математического ожидания), однако,
случайная величина
 ,
равная их среднему арифметическому, с
большой вероятностью примет значение,
близкое к фиксированному числу
,
равная их среднему арифметическому, с
большой вероятностью примет значение,
близкое к фиксированному числу (это среднее всех математических
ожиданий). Это означает следующее. Пусть
в результате испытания независимые
случайные величиныХ
1
,
Х
2
,
… , Х
n
(их много!) приняли значения соответственно
х
1
,
х
2
,
… , х
n
соответственно. Тогда если сами эти
значения могут оказаться далекими от
средних значений соответствующих
случайных величин, их среднее значение
(это среднее всех математических
ожиданий). Это означает следующее. Пусть
в результате испытания независимые
случайные величиныХ
1
,
Х
2
,
… , Х
n
(их много!) приняли значения соответственно
х
1
,
х
2
,
… , х
n
соответственно. Тогда если сами эти
значения могут оказаться далекими от
средних значений соответствующих
случайных величин, их среднее значение
 с большой вероятностью окажется близким
к числу
с большой вероятностью окажется близким
к числу .
Таким образом, среднее арифметическое
большого числа случайных величин уже
теряет случайный характер и может быть
предсказано с большой точностью. Это
можно объяснить тем, что случайные
отклонения значенийХ
i
от a
i
могут быть разных знаков, а потому в в
сумме эти отклонения с большой вероятностью
компенсируются.
.
Таким образом, среднее арифметическое
большого числа случайных величин уже
теряет случайный характер и может быть
предсказано с большой точностью. Это
можно объяснить тем, что случайные
отклонения значенийХ
i
от a
i
могут быть разных знаков, а потому в в
сумме эти отклонения с большой вероятностью
компенсируются.
Терема Чебышева (закон больших чисел в форме Чебышева). Пусть Х 1 , Х 2 , … , Х n … – последовательность попарно независимых случайных величин, дисперсии которых ограничены одним и тем же числом. Тогда, какое бы малое число ε мы ни взяли, вероятность неравенства
будет как угодно близка к единице, если число n случайных величин взять достаточно большим. Формально это означает, что в условиях теоремы
Такой вид сходимости называется сходимостью по вероятности и обозначается:
Таким образом, теорема Чебышева говорит о том, что если есть достаточно большое число независимых случайных величин, то их среднее арифметическое при единичным испытании практически достоверно примет значение, близкое к среднему их математических ожиданий.
Чаще всего теорема Чебышева применяется в ситуации, когда случайные величины Х 1 , Х 2 , … , Х n … имеют одинаковое распределение (т.е. один и тот же закон распределения или одну и ту же плотность вероятности). Фактически это просто большое число экземпляров одной и той же случайной величины.
Следствие (обобщенного неравенства Чебышева). Если независимые случайные величины Х 1 , Х 2 , … , Х n … имеют одинаковое распределение с математическими ожиданиями M (X i )= a и дисперсиями D (X i )= D , то
 ,
т.е.
,
т.е.
 .
.
Доказательство следует из обобщенного неравенства Чебышева переходом к пределу при n →∞ .
Отметим
еще раз, что выписанные выше равенства
не гарантируют, что значение величины
 стремится
ка
при n
→∞.
Эта величина по-прежнему остается
случайной величиной, а ее отдельные
значения могут быть достаточно далекими
от а
.
Но вероятность таких (далеких от а
)
значений с ростом n
стремится к 0.
стремится
ка
при n
→∞.
Эта величина по-прежнему остается
случайной величиной, а ее отдельные
значения могут быть достаточно далекими
от а
.
Но вероятность таких (далеких от а
)
значений с ростом n
стремится к 0.
Замечание . Заключение следствия, очевидно, справедливо и в более общем случае, когда независимые случайные величины Х 1 , Х 2 , … , Х n … имеют различное распределение, но одинаковые математические ожидания (равные а ) и ограниченные в совокупности дисперсии. Это позволяет предсказывать точность измерения некоторой величины, даже если эти измерения выполнены разными приборами.
Рассмотрим
подробнее применение этого следствия
при измерении величин. Проведем некоторым
прибором n
измерений одной и той же величины,
истинное значение которой равно а
и нам неизвестно. Результаты таких
измерений х
1
,
х
2
,
… , х
n
могут значительно отличаться друг от
друга (и от истинного значения а
)
в силу различных случайных факторов
(перепады давления, температуры, случайная
вибрация и т.д.). Рассмотрим с.в. Х
– показание прибора при единичном
измерении величины, а также набор с.в.
Х
1
,
Х
2
,
… , Х
n
– показание прибора при первом, втором,
…, последнем измерении. Таким образом,
каждая из величин Х
1
,
Х
2
,
… , Х
n
есть
просто один из экземпляров с.в. Х
,
а потому все они имеют то же самое
распределение, что и с.в. Х
.
Поскольку результаты измерений не
зависят друг от друга, то с.в.
Х
1
,
Х
2
,
… , Х
n
можно считать независимыми. Если прибор
не дает систематической ошибки (например,
не «сбит» ноль на шкале, не растянута
пружина и т.п.), то можно считать, что
математическое ожидание М(Х)
= а
,
а потому и М(Х
1
)
= ... = М(Х
n
)
= а
.
Таким образом, выполняются условия
приведенного выше следствия, а потому
в качестве приближенного значения
величины а
можно взять «реализацию» случайной
величины
 в нашем эксперименте (заключающемся в
проведении серии изn
измерений), т.е.
в нашем эксперименте (заключающемся в
проведении серии изn
измерений), т.е.
 .
.
При большом числе измерений практически достоверна хорошая точность вычисления по этой формуле. Это является обоснованием того практического принципа, что при большом числе измерений их среднее арифметическое практически почти не отличается от истинного значения измеряемой величины.
На законе больших чисел основан широко применяемый в математической статистике «выборочный» метод, который позволяет по сравнительно небольшой выборке значений случайной величины получать ее объективные характеристики с приемлемой точностью. Но об этом будет рассказано в следующем разделе.
Пример
.
На измерительном приборе, не делающем
систематических искажений, измерена
некоторая величина а
один раз (получено значение х
1
),
а потом еще 99 раз (получены значения х
2
,
… , х
100
).
За истинное значение измерения а
сначала взят результат первого измерения
 ,
а затем среднее арифметическое всех
измерений
,
а затем среднее арифметическое всех
измерений .
Точность измерения прибора такова, что
среднее квадратическое отклонение
измерения σ не более 1 (потому дисперсияD
=σ
2
тоже не превосходит 1). Для каждого из
способов измерения оценить вероятность,
что ошибка измерения не превзойдет 2.
.
Точность измерения прибора такова, что
среднее квадратическое отклонение
измерения σ не более 1 (потому дисперсияD
=σ
2
тоже не превосходит 1). Для каждого из
способов измерения оценить вероятность,
что ошибка измерения не превзойдет 2.
Решение. Пусть с.в. Х – показание прибора при единичном измерении. Тогда по условию М(Х)=а . Для ответа на поставленные вопросы применим обобщенное неравенство Чебышева

при
ε=2
сначала для n
=1
,
а затем для n
=100
.
В первом случае получим
 ,
а во втором.
Таким образом, второй случай практически
гарантирует задаваемую точность
измерения, тогда как первый оставляет
в этом смысле большие сомнения.
,
а во втором.
Таким образом, второй случай практически
гарантирует задаваемую точность
измерения, тогда как первый оставляет
в этом смысле большие сомнения.
Применим приведенные выше утверждения к случайным величинам, возникающим в схеме Бернулли. Напомним суть этой схемы. Пусть производится n независимых испытаний, в каждом из которых некоторое событие А может появиться с одной и той же вероятностью р , а q =1–р (по смыслу это вероятность противоположного события – не появления события А ) . Проведем некоторое число n таких испытаний. Рассмотрим случайные величины: Х 1 – число появлений события А в 1 -ом испытании, …, Х n – число появлений события А в n -ом испытании. Все введенные с.в. могут принимать значения 0 или 1 (событие А в испытании может появиться или нет), причем значение 1 по условию принимается в каждом испытании с вероятностью p (вероятность появления события А в каждом испытании), а значение 0 с вероятностью q = 1 – p . Поэтому эти величины имеют одинаковые законы распределения:
|
Х 1 | ||
|
Х n | ||
Поэтому средние значения этих величин и их дисперсии тоже одинаковы: М(Х 1 )=0 ∙ q +1 ∙ р= р, …, М(Х n )= р ; D (X 1 )=(0 2 ∙ q +1 2 ∙ p )− p 2 = p ∙(1− p )= p ∙ q, … , D (X n )= p ∙ q . Подставляя эти значения в обобщенное неравенство Чебышева, получим
 .
.
Ясно, что с.в. Х =Х 1 +…+Х n – это число появлений события А во всех n испытаниях (как говорят – «число успехов» в n испытаниях). Пусть в проведенных n испытаниях событие А появилось в k из них. Тогда предыдущее неравенство может быть записано в виде
 .
.
Но
величина
 ,
равная отношению числа появлений событияА
в n
независимых испытаниях, к общему числу
испытаний, ранее была названа относительной
частотой события А
в n
испытаниях. Поэтому имеет место
неравенство
,
равная отношению числа появлений событияА
в n
независимых испытаниях, к общему числу
испытаний, ранее была названа относительной
частотой события А
в n
испытаниях. Поэтому имеет место
неравенство
 .
.
Переходя
теперь к пределу при n
→∞,
получим
 ,
т.е.
,
т.е. (по вероятности). Это составляет содержание
закона больших чисел в форме Бернулли.
Из него следует, что при достаточно
большом числе испытанийn
сколь угодно малые отклонения относительной
частоты
(по вероятности). Это составляет содержание
закона больших чисел в форме Бернулли.
Из него следует, что при достаточно
большом числе испытанийn
сколь угодно малые отклонения относительной
частоты
 события от его вероятностир
− почти достоверные события, а большие
отклонения − почти невозможные.
Полученный вывод о такой устойчивости
относительных частот (о которой мы ранее
говорили как об экспериментальном
факте) оправдывает введенное ранее
статистическое определение вероятности
события как числа, около которого
колеблется относительная частота
события.
события от его вероятностир
− почти достоверные события, а большие
отклонения − почти невозможные.
Полученный вывод о такой устойчивости
относительных частот (о которой мы ранее
говорили как об экспериментальном
факте) оправдывает введенное ранее
статистическое определение вероятности
события как числа, около которого
колеблется относительная частота
события.
Учитывая,
что выражение p
∙
q
=
p
∙(1−
p
)=
p
−
p
2
не превосходит
на интервале изменения (в этом легко убедиться, найдя минимум
этой функции на этом отрезке), из
приведенного выше неравенства
(в этом легко убедиться, найдя минимум
этой функции на этом отрезке), из
приведенного выше неравенства легко получить, что
легко получить, что
 ,
,
которое применяется при решении соответствующих задач (одна из них будет приведена ниже).
Пример . Монету подбросили 1000 раз. Оценить вероятность того, что отклонение относительной частоты появления герба от его вероятности будет меньше 0.1.
Решение.
Применяя неравенство
 приp
=
q
=1/2
,
n
=1000
,
ε=0.1
,
получим
.
приp
=
q
=1/2
,
n
=1000
,
ε=0.1
,
получим
.
Пример . Оценить вероятность того, что в условиях предыдущего примера число k выпавших гербов окажется в пределах от 400 до 600 .
Решение.
Условие 400<
k
<600
означает, что 400/1000<
k
/
n
<600/1000
,
т.е.
0.4<
W
n
(A
)<0.6
или
 .
Как мы только что убедились из предыдущего
примера, вероятность такого события не
менее0.975
.
.
Как мы только что убедились из предыдущего
примера, вероятность такого события не
менее0.975
.
Пример . Для вычисления вероятности некоторого события А проведено 1000 экспериментов, в которых событие А появилось 300 раз. Оценить вероятность того, что относительная частота (равная 300/1000=0.3) отстоит от истиной вероятности р не далее, чем на 0.1 .
Решение.
Применяя выписанное выше неравенство
 дляn=1000,
ε=0.1 , получим
.
дляn=1000,
ε=0.1 , получим
.